Single-Stage Visual Relationship Learning using Conditional Queries
UC San Diego1, Intel Labs2
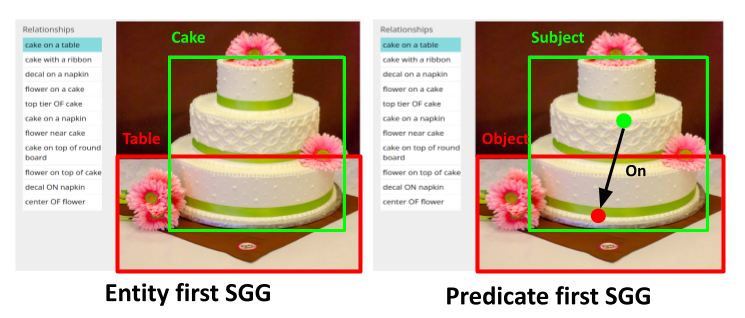
Overview
Research in scene graph generation (SGG) usually considers two-stage models, that is, detecting a set of entities, followed by combining them and labelling all possible relationships. While showing promising results, the pipeline structure induces large parameter and computation overhead, and typically hinders end-to-end optimizations. To address this, recent research attempts to train single-stage models that are computationally efficient. With the advent of DETR[3], a set based detection model, one-stage models attempt to predict a set of subject-predicate-object triplets directly in a single shot. However, SGG is inherently a multi-task learning problem that requires modeling entity and predicate distributions simultaneously. In this paper, we propose Transformers with conditional queries for SGG, namely, TraCQ with a new formulation for SGG that avoids the multi-task learning problem and the combinatorial entity pair distribution. We employ a DETR-based encoder-decoder design and leverage conditional queries to significantly reduce the entity label space as well, which leads to 20% less parameters compared to state-of-the-art single-stage models. Experimental results show that TraCQ not only outperforms existing single-stage scene graph generation methods, it also beats many state-ofthe-art two-stage methods on Visual Genome dataset, yet is capable of end-to-end training and faster inference.

Published in Neural Information Processing Systems (NeurIPS), 2022
Model
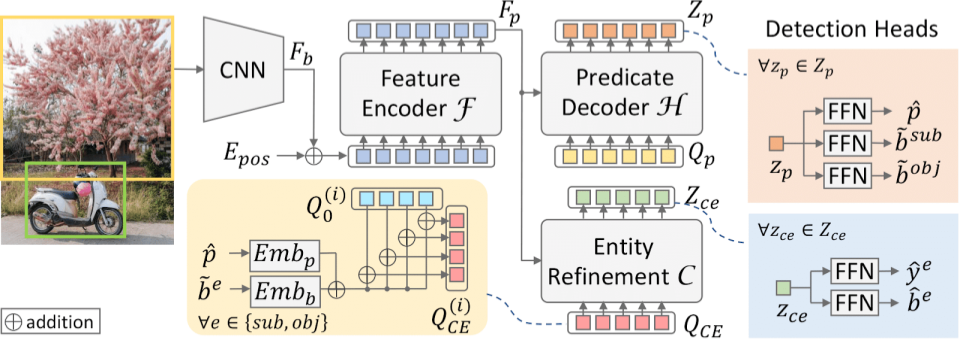
Transformers with conditional queries TraCQ is composed of a transformer based feature extractor F and predicate decoder H for directly detecting the predicates first. Finally, conditional entity refinement decoder C performs boundung box refinement and labeling, which significantly reduce the entity label space while limiting combinatorial entity pair space for the model.
Code
The code for training and evaluation and the model parameters will be available on GitHub (comming soon).
Results
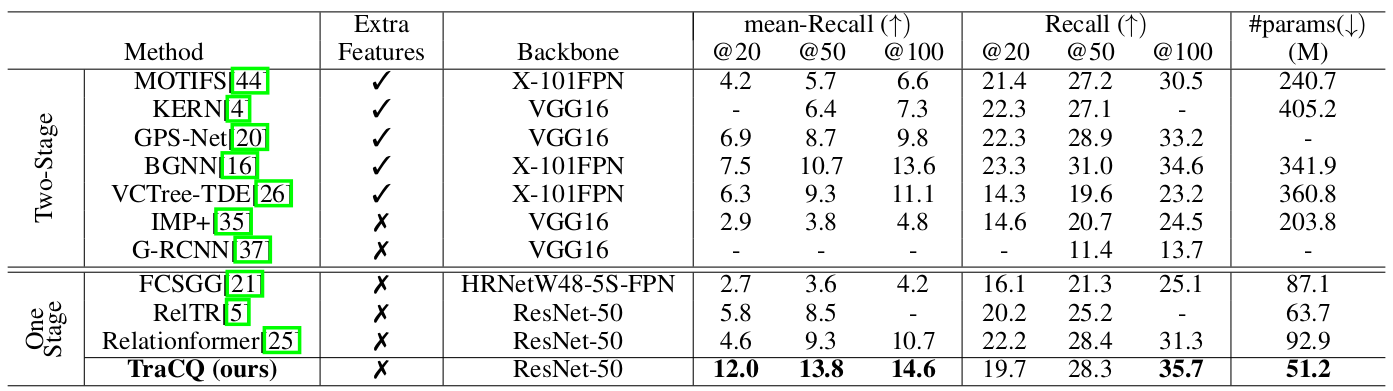
TraCQ significantly outperforms existing single-stage methods, and several state-of-the-art two-stage methods as well.
Please refer to our paper for more ablations.
Visualization
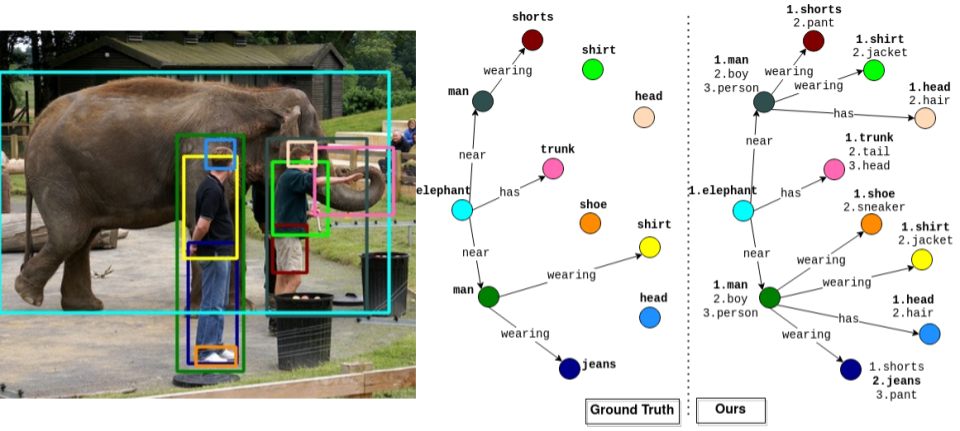
In each sub-figure, colors of bounding boxes in the image (left) are corresponding to the entities (nodes) in the triplets. Text in red indicates incorrect/missed relation/entity.
Scene Graph Generation (SGG)
Visual example generated by TraCQ shows that it can generate meaningful descriptions of the scene. TracQ can predict reasonable relations that are missing in ground-truth annotations. For example, TraCQ predicts wearing as the predicate between man (dark green box) and shoe (orange box), while the annotation is missing in the ground truth.
Acknowledgements
This work was partially funded by NSF awards IIS1924937 and IIS-2041009, a gift from Amazon, a gift from Qualcomm, and NVIDIA GPU donations.