Audio-Visual Self-Supervised Learning

Overview
Imagine the sound of waves. This sound may evoke the memories of days at the beach. A single sound serves as a bridge to connect multiple instances of a visual scene. It can group scenes that ’go together’ and set apart the ones that do not. Co-occurring sensory signals can thus be used as a target to learn powerful representations for visual inputs without relying on costly human annotations. This project introduces effective self-supervised learning methods that curb the need for human supervision. We introduce an effective contrastive learning framework that learns from the natural associations between audio and visual data. We identify and propose solutions for critical challenges inherent to type of supervision. In particular, the presence of noisy audio-visual associations, and the lack of spatial grounding of sound signals in normal video. Furthermore, in this project, we discuss several tasks that benefit from audio-visual learning, including representation learning for action and audio recognition, visually-driven sound source localization, and spatial sound generation.
Projects
Audio Visual Instance Discrimination
This project presents a contrastive learning framework for cross-modal discrimination of video from audio and vice-versa. We show that optimizing for cross-modal discrimination, rather than within-modal discrimination, is important to learn good representations. With this simple but powerful insight, our method achieves highly competitive performance when finetuned on action recognition tasks. We also generalize the definition of positive associations beyond instances by exploring cross-modal agreements. Similar instances in both the video and audio feature spaces are grouped together to form the instance's positive set. We show that cross-modal agreement creates better positive sets for contrastive learning, allowing us to calibrate visual similarities by seeking within-modal discrimination of positive instances, and achieve significant gains on downstream tasks.
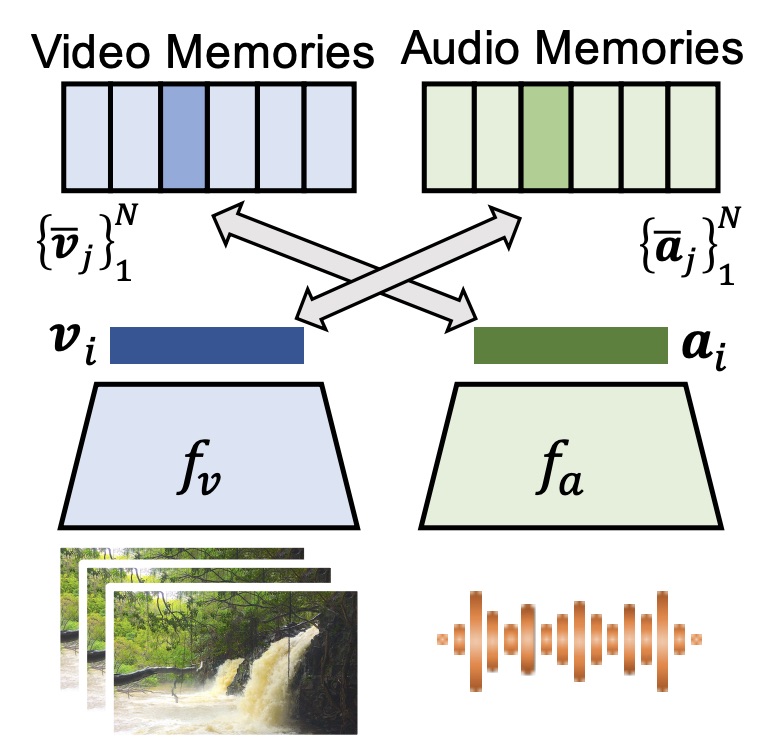
Robust Cross-Modal Instance Discrimination
Cross-modal instance discrimination approaches introduce two sources of training noise: uncorrelated audio and video signals within the same instance produce faulty positives; faulty random sampling of negative instances yield faulty negatives (i.e. negatives that are semantically similar to the base instance). In this project, we study the detrimental impact of these two sources of training noise, and propose solutions for them. We validate our contributions through extensive experiments on action recognition tasks and show that they address the problems of audio-visual instance discrimination and improve transfer learning performance.

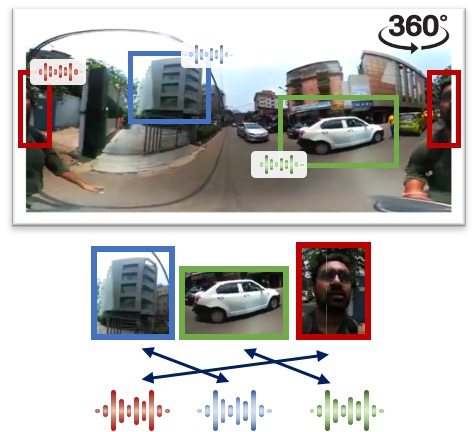
Audio-Visual Spatial Alignment
Methods such as audio-visual instance discrimination predict whether audio and video clips originate from the same or different video instances. While these approaches learn high-quality representations for downstream tasks such as action recognition, their training objectives disregard spatial cues naturally occurring in audio and visual signals. To learn from these spatial cues, we proposed the audio-visual spatial alignment task, which requires the model to reason about local correspondences. We also introduce a cross-modal feature translation architecture inspired by transformers that is capable of reasoning over the full spatial content of the 360 video.
Spatial Audio Generation
Beyond representation learning, we also studied how well local associations between audio and visual signals can be predicted, not just as a means to learn visual models but as an end in itself. To showcase this ability, we introduce an approach that converts mono audio recorded by a 360° video camera into spatial audio, a representation of the distribution of sound over the full viewing sphere. Inspired by the spatial audio generation process, we developed an effective architecture for this task that performs sound source separation and localization independently. Using our approach, we show that it is possible to infer the spatial location of sound sources based only on 360° video and a mono audio track.

Publications
Learning to see and hear without human supervision
Pedro Morgado
Ph.D. Thesis, University of California San Diego,
2021.
Robust Audio-Visual Instance Discrimination
Pedro Morgado, Ishan Misra and Nuno Vasconcelos
IEEE/CVF Conf. on Computer Vision and Pattern Recognition (CVPR),
2021.
Audio-Visual Instance Discrimination with Cross-Modal Agreement
Pedro Morgado, Nuno Vasconcelos and Ishan Misra
IEEE/CVF Conf. on Computer Vision and Pattern Recognition (CVPR),
2021.
Learning Representations from Audio-Visual Spatial Alignment
Pedro Morgado*, Yi Li* and Nuno Vasconcelos
Advances in Neural Information Processing Systems (NeurIPS),
2020.
Self-Supervised Generation of Spatial Audio for 360° Video
Pedro Morgado, Nuno Vasconcelos, Timothy Langlois and Oliver Wang
Advances in Neural Information Processing Systems (NeurIPS),
Montreal, Canada, 2018.
Acknowledgements
This work was partially funded by graduate fellowship SFRH/BD/109135/2015 from the Portuguese Ministry of Sciences and Education, NRI Grant IIS-1637941, NSF awards IIS-1924937, IIS-2041009, and gifts from NVIDIA, Amazon and Qualcomm. We also acknowledge and thank the use of the Nautilus platform for some of the experiments in the papers above.