Breadcrumbs: Adversarial Class-balanced Sampling for Long-tailed Recognition
Haoxiang Li2
Hao Kang2
Gang Hua2
UC San Diego1, Wormpex AI Research2
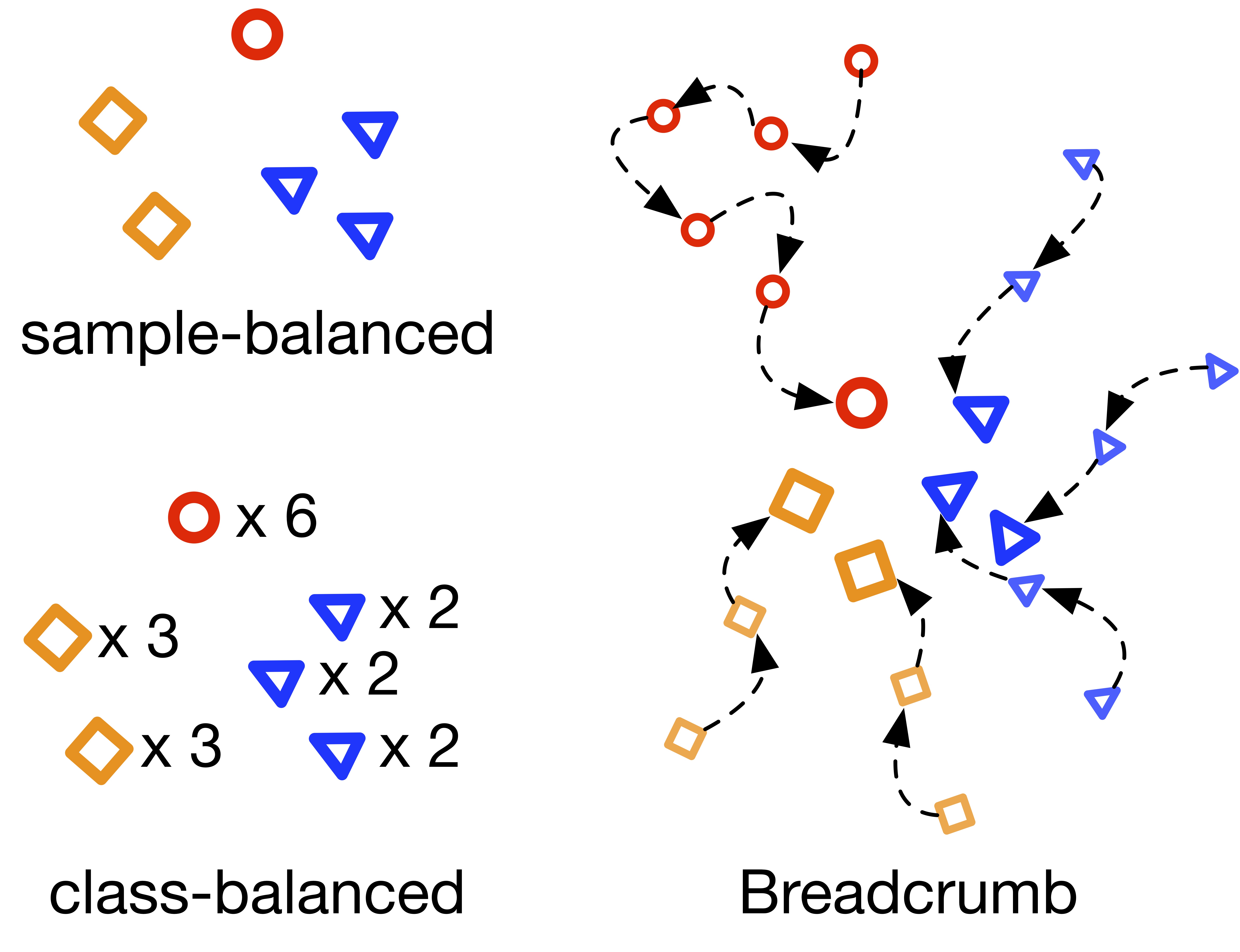
Overview
The problem of long-tailed recognition, where the number of examples per class is highly unbalanced, is considered. While training with class-balanced sampling has been shown effective for this problem, it is known to over-fit to few-shot classes. It is hypothesized that this is due to the repeated sampling of examples and can be addressed by feature space augmentation. A new feature augmentation strategy, EMANATE, based on back-tracking of features across epochs during training, is proposed. It is shown that, unlike class-balanced sampling, this is an adversarial augmentation strategy. A new sampling procedure, Breadcrumb, is then introduced to implement adversarial class-balanced sampling without extra computation. Experiments on three popular long-tailed recognition datasets show that Breadcrumb training produces classifiers that outperform existing solutions to the problem.

Models
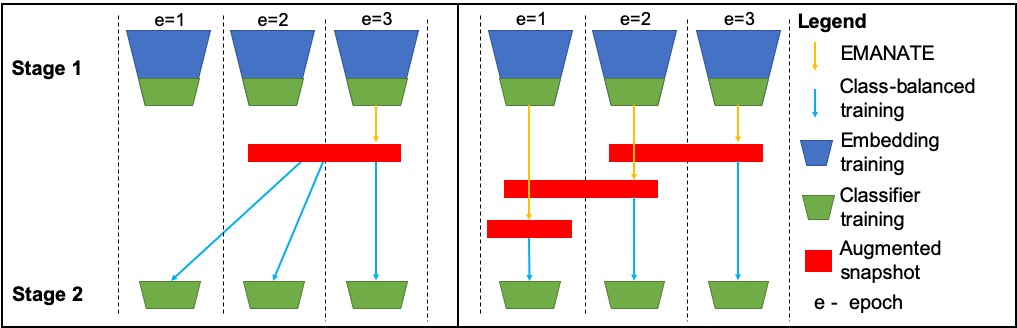
Architecture: Schematic representation of Breadcrumbs.
Highlights
- fEature augmentAtioN by back-trAcking wiTh alignmEnt (EMENATE): adversarial feature augmentation.
- Feature back-tracking.
- Class-specific augmentation.
- Class alignment.
- Assembling: tracking features from all epochs.
Code
Training, evaluation and deployment code available on GitHub.
Authors


Haoxiang Li
Wormpex AI Research

Hao Kang
Wormpex AI Research

Gang Hua
Wormpex AI Research

Acknowledgements
Gang Hua was supported partly by National Key R&D Program of China Grant 2018AAA0101400 and NSFC Grant 61629301. Bo Liu and Nuno Vasconcelos were partially supported by NSF awards IIS-1637941, IIS-1924937, and NVIDIA GPU donations.