![]()
| Home | People | Research | Publications | Demos |
| News | Jobs |
Prospective
Students |
About | Internal |

Holistic Context Models: Retrieval Results |
|
Quantitative Results |
|
| Finally, the benefits of holistic context modeling were evaluated on the task of content based image retrieval, using the well known query-by-example paradigm. This is a nearest-neighbor classifier, where a vector of global image features extracted from a query image is used to retrieve the images of closest feature vector in an image database. In previous work, we have shown that state-of-the-art results for this type of operation are obtained by using appearance-level posterior distributions (SMNs) as feature vectors. In this work, we compare results of using the distributions obtained at the contextual (CMN) and appearance (SMN) levels. The similarity between the distributions of the query and database images is measured with the Kullback-Leibler divergence. | |
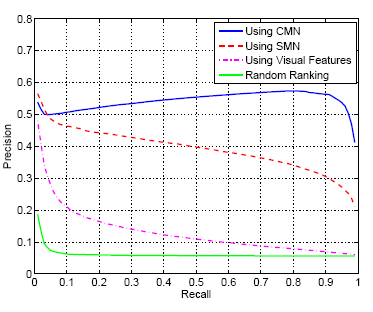
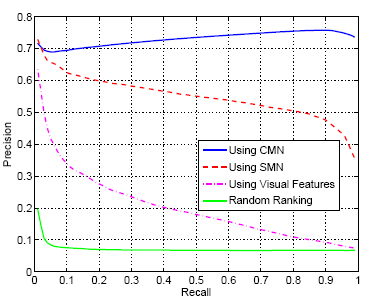 Figure.1 |
|
|
Figure.1, presents precision-recall (PR) curves on C15 and F18.
Also shown are the performance of the image matching system
which is based on the MPE retrieval principle now
used but does not rely on semantic modeling, and chance-level
retrieval. Note how the precision of contextual modeling
is |
|
Some Examples |
|
    Figure.2 |
|
| Figure.2 illustrates the improved generalization of contextual modeling. It presents retrieval results for the three systems (top three rows of every query show the top retrieved images using visual matching, SMN, and CMN respectively). The first column shows the queries while the remaining columns show the top five retrieved images. Note how visual matching has no ability to bridge the semantic gap, simply matching semantically unrelated images of similar color and texture. This is unlike the semantic representations (SMN and CMN) which are much more effective at bridging the gap, leading to a much smaller number of semantically irrelevant matches. In particular, the ability of the CMN-based system to retrieve images in the query's class is quite impressive, given the high variability of visual appearance. | |
![]()
©
SVCL