![]()
| Home | People | Research | Publications | Demos |
| News | Jobs |
Prospective
Students |
About | Internal |

Holistic Context Models: System Parameters |
|
Performance of the context models as a function of: |
|
| Choice of Appearance Features: Table.1 compares the classification performance of the three appearance representations. In all cases, the contextual models yield improved performance, with a gain of 7.7%, 5.9% and over 54% for SIFT-GRID, SIFT-INTR and DCT, respectively. Note that the contextual models achieve high performance (over $72%$) for all appearance features. More interestingly, this performance is almost unaffected by that of the underlying appearance classification, in the sense that very large variations in the latter lead to relatively small differences in the former. | |
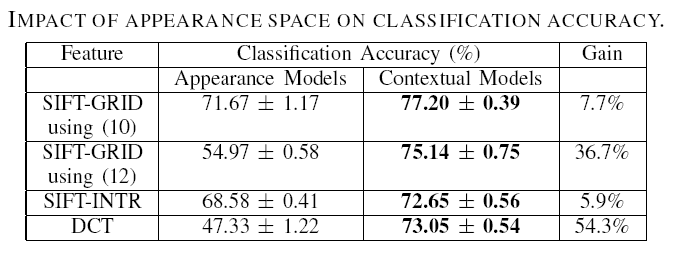 Table 1 |
|
|
This hypothesis was studied in greater detail, by measuring how
contextual-level performance depends on the ``quality'' of the appearance
classification. The number of Gaussian components in the appearance models
was the parameter adopted to control this ``quality''.
Figure.1 shows that decreasing this parameter
leads to a Overall, the performance of the contextual classifier is not even strongly affected by the feature transformation adopted. While, at the appearance level, the performance of the DCT is not comparable to that of SIFT, the choice of transform is much less critical when contextual modeling is included: the two transforms lead to similar performance at the contextual level. This suggests that 1) any reasonable architecture could, in principle, be adopted for appearance classification, and 2) there is no need for extensive optimization at this level. This is an interesting conclusion, given that accurate appearance classification has been a central theme in the recognition literature over the last decades. |
|
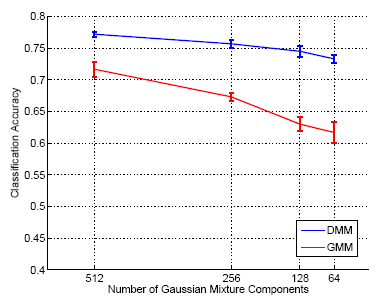
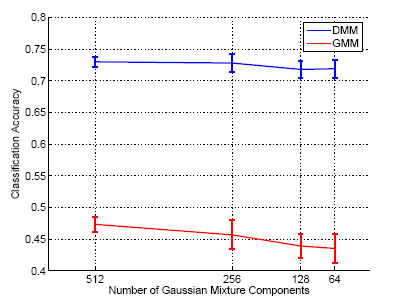 Figure 1 |
|
| Number of Mixture Components: Figure.2 presents the classification performance as a function of the number of contextual mixture components, for SIFT-GRID, SIFT-INTR and DCT features. In all cases, a single Dirichlet distribution is insufficient to model the semantic co-occurrences of N15. As the number of mixture components increases from 1 to 8, performance rises substantially for SIFT (e.g. from 72.58% to 76.13% for SIFT-GRID), and dramatically (from 55.93% to 70.48%) for the DCT. Above 8 components, the gain is moderate in all cases, with a maximum accuracy of 77.20% for SIFT-GRID and 73.05% for the DCT. | |
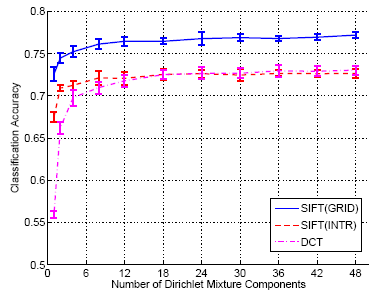 Figure.2 |
|
![]()
©
SVCL