![]()
| Home | People | Research | Publications | Demos |
| News | Jobs |
Prospective
Students |
About | Internal |

| Cross-Modal Multimedia Retrieval | |
|
|
|
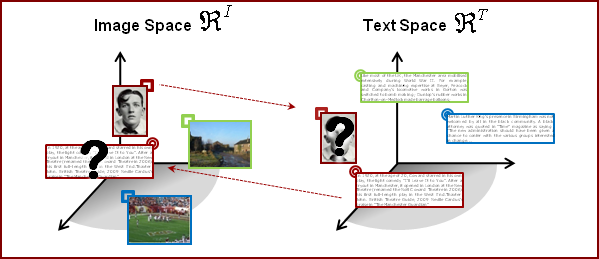
Starting from the extensive literature available on text and image analysis, including the representation of documents as bags of features (word histograms for text, SIFT histograms for images), and the use of topic models (such as latent Dirichlet allocation) to extract low-dimensionality generalizations from document corpora. We build on these representations to design a joint model for images and text. The performance of this model is evaluated on a crossmodal retrieval problem that includes two tasks: 1) the retrieval of text documents in response to a query image, and 2) the retrieval of images in response to a query text. These tasks are central to many applications of practical interest, such as finding on the web the picture that best illustrates a given text (e.g., to illustrate a page of a story book), finding the texts that best match a given picture (e.g., a set of vacation accounts about a given landmark), or searching using a combination of text and images. We use performance on the retrieval tasks as an indirect measure of the model quality, under the intuition that the best model should produce the highest retrieval accuracies. Whenever the image and text spaces have a natural correspondence, cross-modal retrieval reduces to a classical retrieval problem. However, the text component is represented as a sample from a hidden topic model, learned with latent Dirichlet allocation, and images are represented as bags of visual (SIFT) features. These representations evidently lack a common feature space. Therefore the question is how to establish correspondence between two modality feature spaces. |
|
|
|
|
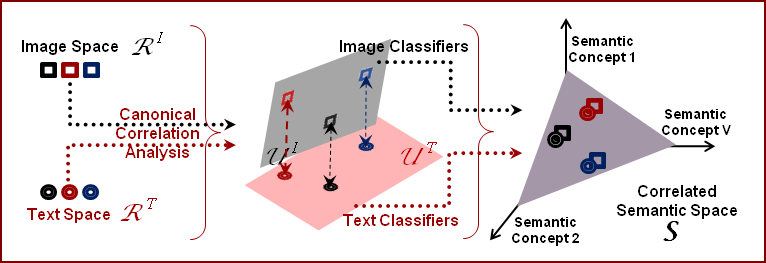
Two hypotheses are investigated: that
1) there is a benefit to explicitly modeling correlations between the two components, and
2) this modeling is more effective in feature spaces with higher levels of abstraction.
|
|
| Database: |
We have colected the following dataset for cross-modal retrieval experiments:
The final corpus contains 2,866 multimedia documents. The median text length is 200 words. |
| Code: |
Please check links under the Publications section below. |
| Publications: |
On the Role of Correlation and Abstraction in Cross-Modal Multimedia Retrieval J. Costa Pereira, E. Coviello, G. Doyle, N. Rasiwasia, G. Lanckriet, R.Levy and N. Vasconcelos IEEE Transactions on Pattern Analysis and Machine Intelligence Vol. 36(3), pp. 521-535, March 2014 © IEEE [ps] [pdf] [BibTeX] |
|
A New Approach to Cross-Modal Multimedia Retrieval (Best student paper award ACM-MM 2010) N. Rasiwasia, J. Costa Pereira, E. Coviello, G. Doyle, G. Lanckriet, R.Levy and N. Vasconcelos ACM Proceedings of the 18th International Conference on Multimedia Florence, Italy - Oct. 2010 © ACM [ps] [pdf] [BibTeX] [code] |
|
| Presentations: |
A New Approach to Cross-Modal Multimedia Retrieval N. Rasiwasia ACM Proceedings of the 18th International Conference on Multimedia Florence, Italy. October 27, 2010. [ppt] |
| Contact: | Jose Costa Pereira, Nikhil Rasiwasia or Nuno Vasconcelos |
![]()
©
SVCL