![]()
| Home | People | Research | Publications | Demos |
| News | Jobs |
Prospective
Students |
About | Internal |

Dynamic Pooling for Complex Event Recognition
The recent focus in video understanding has turned from recognition of primitive or atomic actions to that of the open-source video sequences. While the former typically concerns instantanesou motion such as "walking", "running", or "jumping", from carefully assembled video, the latter involves complex events that depict human behaviors in unconstraint scenes and more sophisticated activities, which contain more complex interactions with the environment, e.g., a "wedding ceremony", a "parade" or a "birthday party". Due to the tremendous variability in the open-source video composition (e.g., diverse recording setting, inhomogeneous post-processing), the detection of complex events presents two major challenges beyond those commonly addressed in the action recognition literature: 1) a long sequence is usually not precisely segmented to include only the content of interest; and 2) target events can have a complex temporal structure. In general, a complex event can have multiple behaviors and these can appear with great variability of temporal configurations.
In the action recognition literature, the popular bag of (visual) features (BoF) representation has been shown to 1) produce robust detectors for various classes of activities, and 2) serve as a sensible basis for more sophisticated representations. One operation critical for its success is the pooling of visual features into a holistic video representation. However, while fixed pooling strategies, such as average pooling or temporal pyramid matching, are suitable for carefully manicured video, they have two strong limitations for complex event recognition. First, by integrating information in a pre-defined manner, they cannot adapt to the temporal structure of the behaviors of interest. Second, by pooling features from video regions that do not depict characteristic behaviors, they produce noisy histograms, where the feature counts due to characteristic behavior can be easily overwhelmed by those due to uninformative content.
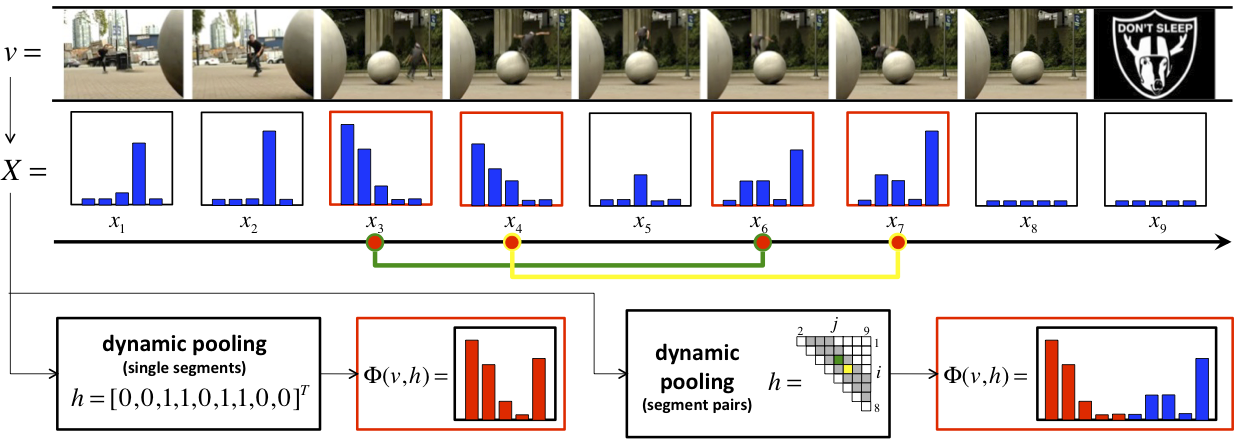
In this work, we address both limitations by proposing a pooling scheme adaptive to the temporal structure of the particular video to recognize. The video sequence is decomposed into segments, and the most informative segments for detection of a given event are identified, so as to dynamically determine the pooling operator most suited for that particular video sequence. This dynamic pooling is implemented by treating the locations of the characteristic segments as hidden information, which is inferred, on a sequence-by-sequence basis, via a large-margin classification rule with latent variables. While this entails a combinatorial optimization, we show that an exact solution can be obtained efficiently, by solving a series of linear programming. In this way, only the portions of the video informative about the event of interest are used for its representation. The proposed pooling scheme can be seen either as 1) a discriminant form of segmentation and grouping, which eliminates histogram noise due to uninformative content, or 2) a discriminant approach to modeling video structure, which automatically identifies the locations of behaviors of interest.
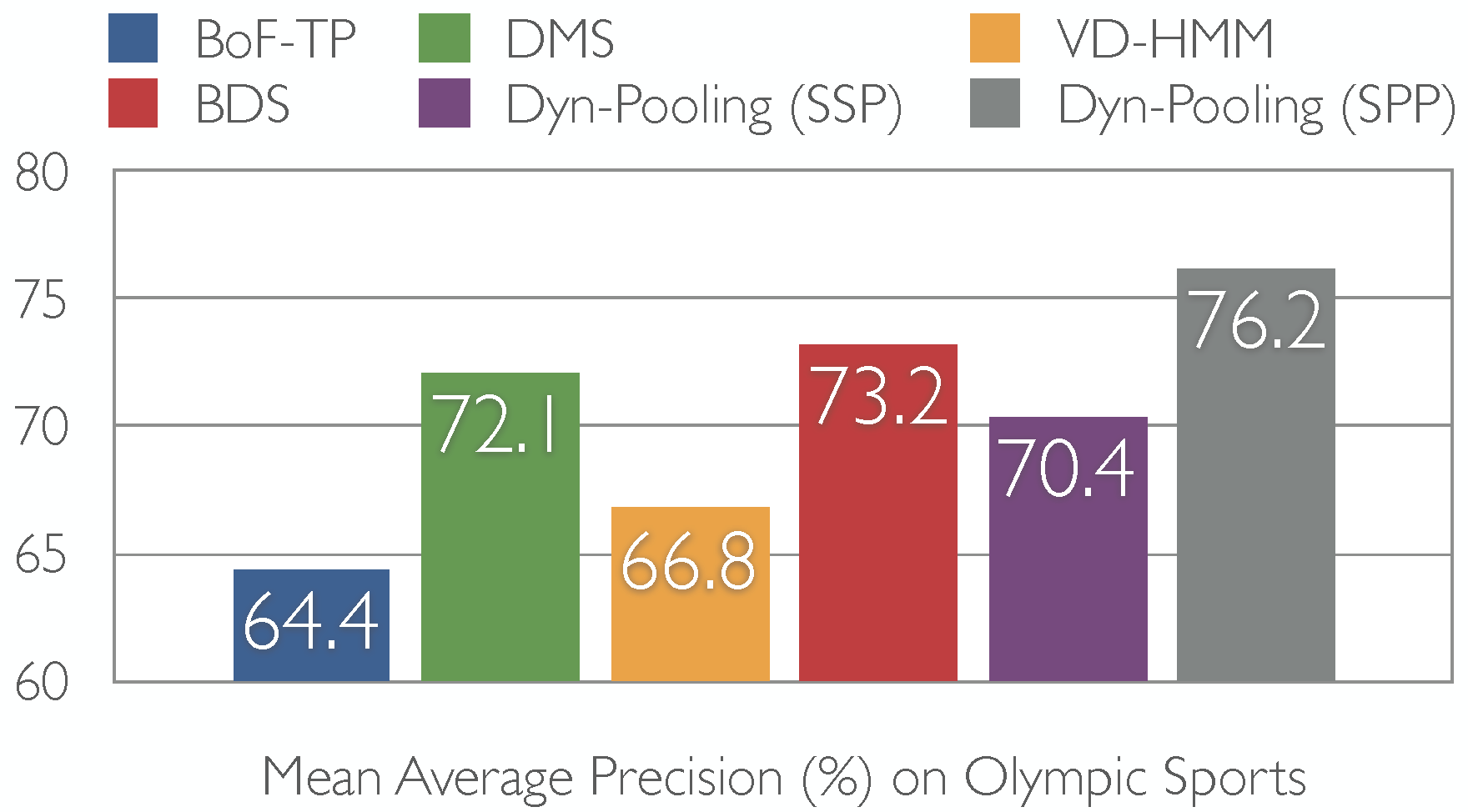
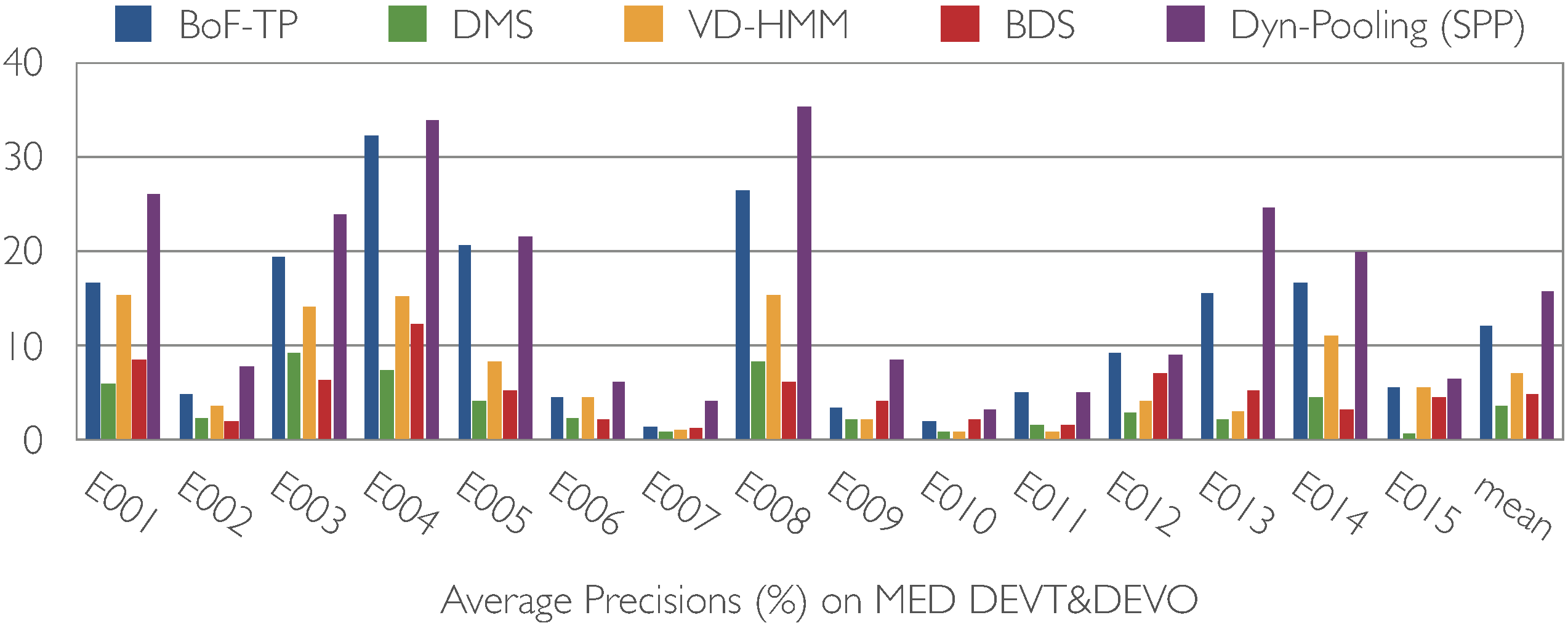
| Two schemes of the porposed dynamic pooling strategy, the single segment pooling (SSP) and the segment pair pooling (SPP), are shown to significantly outperform previous state-of-the-art models of video temporal structure on two compelx event benchmarks, Olympic sports and TRECVID multimedia event detection (MED). These include the popular bag-of-visual words temporal pooling (BoF-TP) by Laptev et al 2008, decomposible motion segments (DMS) by Niebles et al 2010, variable-duration hidden Markov model (VD-HMM) by Tang et al 2012, and binary dynamic systems (BDS) of our previous work (see the publications for details). |
|
|
|
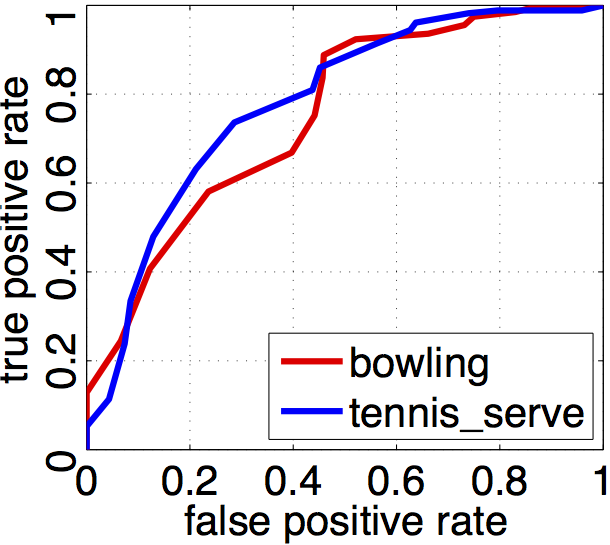
Besides the complex event recogniton, the proposed dynamic pooling framework
also enables adaptive video
segmentation according to the target event.
This is evaluated either
|
|
Dynamic Pooling for Complex Event Recognition
Wei-Xin LI,
Qian Yu,
Ajay Divakaran
and
Nuno Vasconcelos
Proc. of
IEEE International Conf. on Computer Vision (ICCV)
Sydney, New South Wales, Australia, 2013
[
pdf |
DOI |
BibTeX
]
Multiple Instance Learning for Soft Bags via To Instances
Wei-Xin LI,
and
Nuno Vasconcelos
Proc. of IEEE Conf. on Computer Vision and Pattern Recognition (CVPR)
Boston, Massachusetts, United States, 2015
[
pdf |
DOI |
BibTeX
]
![]()
©
SVCL