![]()
| Home | People | Research | Publications | Demos |
| News | Jobs |
Prospective
Students |
About | Internal |

|
Generalized Stauffer-Grimson Background Subtraction for Dynamic Scenes
Antoni Chan, Vijay Mahadevan, and Nuno Vasconcelos |
|||||||||||||||
|
This page contains the video results for the paper "Generalized Stauffer-Grimson Background Subtraction for Dynamic Scenes". The video are encoded in Quicktime h.264 (.mov playable with the latest Quicktime player), or DivX (.avi playable by Windows Media Player with DivX codec). Several different background models are tested (see the paper for more details):
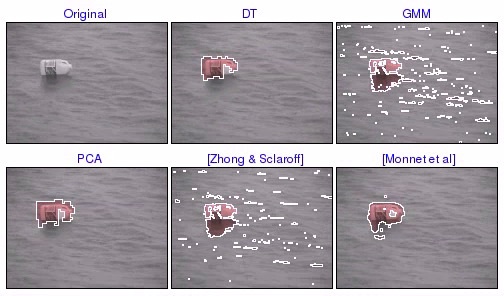 [ mov (1.7 MB) | avi (2.6 MB) ] The DT model performs significantly better than the GMM, at 80% TPR, the DT model has a false-positive rate of 0.21%, while the GMM has a false-positive rate of 2.36%. Note that the DT model is non-adaptive, and yet still models the background motion well. On the other hand, GMM is an adaptive model, but it is ill-suited for modeling the stochastic nature of water motion. The PCA model also performs well, but is slightly inferior to DT. This suggests that the water background of Bottle is modeled well with texture, and that the improvement in performance of the DT is due to its ability to also model the motion of the texture. [Monnet et al], which is based on single-step prediction of the PCA coefficients, also outperforms the PCA model. Note that the pixel-based methods (GMM and [Zhong & Sclaroff]) mark most of the reflection of the bottle as foreground, whereas the patch-based methods (DT, PCA, and [Monnet et al]) mark the reflection as background water. Again, this illustrates the importance of modeling the texture along with the motion.
 [ mov (10 MB) | avi (15 MB) ]  [ mov (12 MB) | avi (15 MB) ] DTM3 is able to model the wake of the boat with a new mixture component, and correctly adapts it into the background quickly. On the other hand, the adaptive model with a single dynamic texture (DTM1) takes much longer to adapt to the wake because the model only contains a single mode. While the models based on dynamic textures tend to do well on these video, the other background models perform fairly poorly. GMM is able to adapt to the wake of the boat, but the overall foreground detections are very noisy, due to the constant motion of the waves. [Monnet et al] detects the wake as part of the foreground, and has trouble with the stochastic nature of the shimmering waves in the bottom of the video.
 [ mov (5.8 MB) | avi (9.9 MB) ] DTM3 marks the boat region as foreground, while ignoring the wake of the boat. In addition, the boat is still marked as foreground, even when it is small, relative to the waves in the other portions of the scene. This is in contrast to the GMM, which contains a significant amount of false detections. In particular, when the boat is small, the detected foreground region of the boat is very similar in shape and size to the false detections. These types of errors will make processing in a subsequent tracking stage very difficult. On the other hand, DTM3 performs well regardless of the scale of the boat, and maintains a very low false positive rate throughout the video.
 [ mov (1.0 MB) | avi (1.7 MB) ] DTM3 is able to adapt to the motion of the ocean, while still detecting the foreground objects. On the other hand, the crashing waves cause false detections by the GMM.
 [ mov (0.4 MB) | avi (0.5 MB) ] The helicopter is marked as foreground by the model, while the smoke is marked as background.
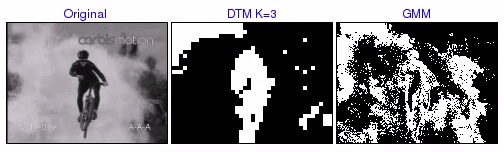
 [ mov (2.7 MB) | avi (5.3 MB) ] DTM3 successfully marks the skiers as foreground, but exhibits some errors when there is a significant amount of camera pan (e.g. the last two frames). On the other hand, the foreground detected by GMM contains a significant amount of noise, due to both the falling snow and the camera pan, and fails to find the skiers when they are small.
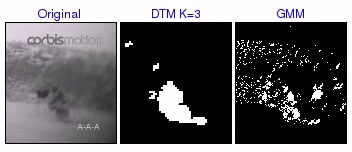
 [ mov (1.9 MB) | avi (3.2 MB) ] This shows a case where DTM3 is adapting quickly to an unseen background motion. The beginning of the explosion is detected as foreground because it is an unseen motion process. As the explosion propagates outward, the areas within the explosion are marked as background as they adapt to the new motion. Meanwhile, the biker is still marked as foreground. Finally, after sufficient exposure, the explosion no longer registers as foreground, leaving only the biker as the detected foreground. Looking at the results using GMM, the detected foreground again contains significant noise, indicating that the stochastic nature of the explosion is poorly modeled by the GMM pixel process. |
|||||||||||||||
![]()
©
SVCL