![]()
| Home | People | Research | Publications | Demos |
| News | Jobs |
Prospective
Students |
About | Internal |

| Panda Detection | ||
 |
||
| Finetune: |
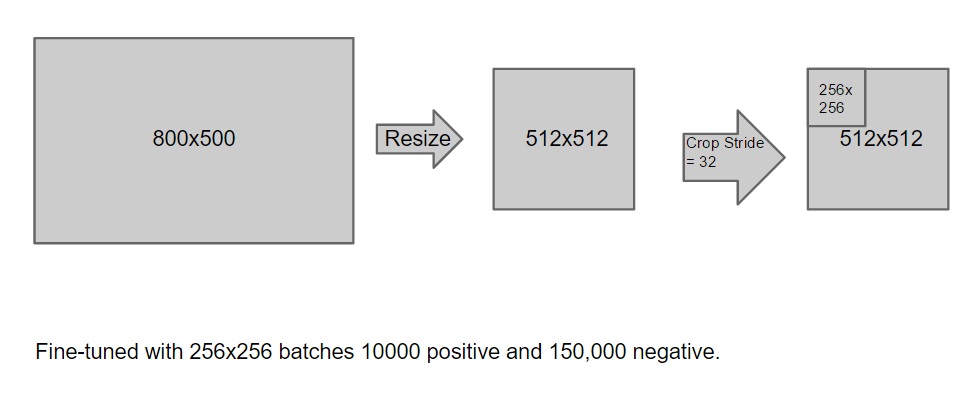
The size of the original images captured from Panda Cam are 805*500, we then resized all the images to 512*512. 256*256 image batches are then cropped from each of the 512*512 image with 32 pixels step size. Given this structure, there are 8*8 batches per image. We then label all the image batches for fine-tuning. Note that the original model being used is the reference caffenet and we fine-tuned our model on top of it. In our case, we use 10,000 positive image batches (batches that have panda in it) and 150,000 negative image batches. (batches that does not contain panda) |
|
| Testing: |
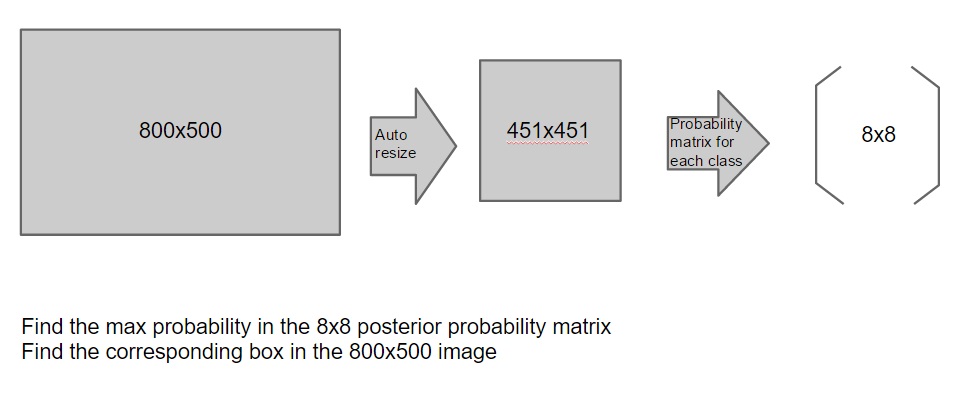
In order to utilize caffe for object detection (localization), a net surgery is done to the last 3 layers when testing. Namely, the inner product layers, fc6, fc7 and fc8 are all replaced with convolutional layers, fc6-conv, fc7-conv and fc8-conv. Consequently, an 8*8 matrix will be returned instead of a single number. Each entry in the 8*8 matrix can be interpret as the probability of the corresponding image batch having a panda. This is equivalent to breaking a large image into small pieces, and see if any one of those pieces contain panda. In order to locate the panda, we find out the largest entry in the 8*8 matrix and then we set a threshold. If the maximum probability exceed the threshold, then we put a box around the corresponding batches in the original image, as seen in the first picture. |
|
| Results: |
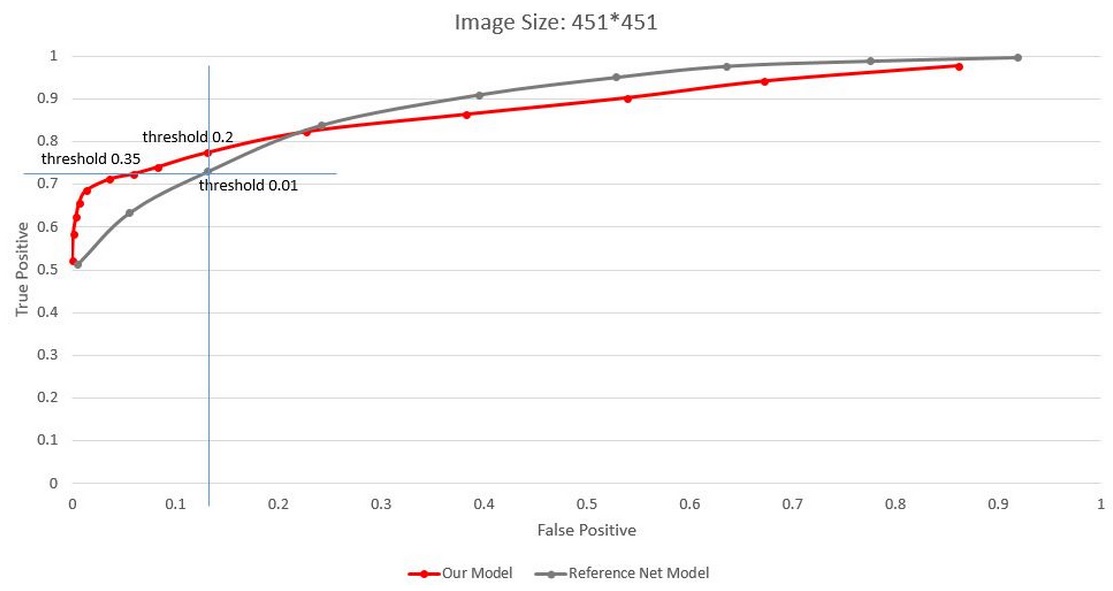
As seen from the graph, at the same false positive (no pandas in the picture but the detector gives positive results) rate 0.13 , our model achieves a higher detection rate, 0.77 compared to 0.73 of the reference model. Note that the threshold of the two models are incomparable since the reference model has 1000 classes but we fine tuned our model to contain only 2. At the same detection rate 0.73, our model achieves a lower false positive rate 0.06 compared to that of the reference model 0.13. |
|
| Video: |
(Posted on 11/5/2015) For more panda detection videos, please visit our YouTube channel. |
|
| Contact: |
Nuno Vasconcelos Mandar Dixit Tseng Chou Ka Wai Chen Fei Deng |
|
![]()
©
SVCL