![]()
| Home | People | Research | Publications | Demos |
| News | Jobs |
Prospective
Students |
About | Internal |

Databases |
|
|
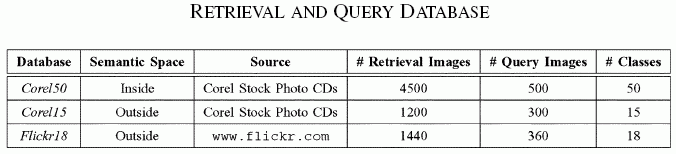
The evaluation of a QBSE system requires three databases: a training database, used by the semantic labeling system to learn concept probabilities, a retrieval database, from which images are to be retrieved, and a database of query images, which plays the role of test set. Training DatabaseThe Corel dataset was the training database for all experiments. This dataset, henceforth referred to as Corel50, consists of 5, 000 images from 50 Corel Stock Photo CDs, divided into a training set of 4, 500 images (used to learn the semantic space), and a test set of 500 images (not used in the learning stage). Each CD includes 100 images of a common topic, and each image is labeled with 1-5 semantic concepts. Overall there are 371 keywords in the data set, leading to a 371-dimensional semantic simplex. All images were represented as bags of 8 × 8 vectors of discrete cosine transform (DCT) coefficients, extracted from the three channels of the YBR color space. The parameters of the semantic class mixture hierarchies were learned in the subspace of the first 21 DCT coefficients from each channel. Retrieval and Query DatabaseRetrieval performance was evaluated on three databases Corel50, Flickr18 and Corel151. Inside the semantic space Corel50 served as both retrieval and query database. More precisely, the 4500 training images served as the retrieval database and the remaining 500 as the query database. Outside the semantic space, we used the two other databases. Corel15, consists of 1, 500 images from 15 previously unused Corel CDs. Flickr18, was collected on-line (from www.flickr.com) and contains 1800 images divided into 18 classes according to the manual annotations provided by the online users. These images are shot by flickr users, and hence differ from the Corel Stock photos, which have been shot professionally. In both cases, 20% of randomly selected images served as queries and the remaining 80% as the retrieval database. The QBVE system only requires a query and a retrieval database, which were, in all experiments, made identical to the query and retrieval databases used by the QBSE system. | |
Databases
| |
![]()
©
SVCL