
| Home | People | Research | Publications | Demos |
| News | Jobs |
Prospective Students |
About | Internal |

| Query by Semantic Example (Demo) | |
|
|
|
Two main content based image retrieval paradigms have evolved over the years: one based on visual queries,
or query-by-visual-example (QBVE), and the other based
on textual queries, or semantic retrieval . Early
retrieval architectures were almost exclusively based on the visual retrieval
framework. Under this paradigm, each image is decomposed into a number of low-level visual
features (e.g. a color histogram), and retrieval implemented through
query-by-example. This consists of specifying the query as the feature
vector extracted from an image, and searching the database for the best match
to that feature vector. It was, however, quickly realized that strict visual similarity is, in most cases, weakly
correlated with the similarity criteria adopted by humans
for image comparison.
This motivated the more ambitious goal of designing retrieval systems with
support for semantic queries. The basic idea is to
annotate images with semantic keywords, enabling users to specify their
queries through natural language descriptions. This idea was extended to the design of semantic spaces,
i.e. spaces whose dimensions are the semantic concepts known to the
retrieval system. The earliest among such systems
were based on semantic information extracted from image
metadata. Later on, semantic spaces were also
constructed with resort to active learning, based on user relevance
feedback. Because manual supervision is labor intensive,
much of the research turned to the problem of automatically extracting
semantic descriptors from images, by application of machine learning
algorithms. Early efforts targeted the extraction of specific
semantics. More recently, there has been an effort to
solve the problem in greater generality, through the design of techniques
capable of learning relatively large semantic vocabularies from informally
annotated training image collections.
When compared to QBVE, semantic retrieval systems have the advantages of 1) a
higher level of abstraction, and 2) easier query specification (through the use
of natural language). They are, nevertheless, restricted by the size of
their vocabularies, and the fact that most images have multiple semantic
interpretations. None of these limitations afflict QBVE, which also tends
to enable more intuitive implementation of interactive functions, such as
relevance feedback. In this work we show that, through the simple extension
of the query-by-example paradigm to the semantic domain, it is possible to
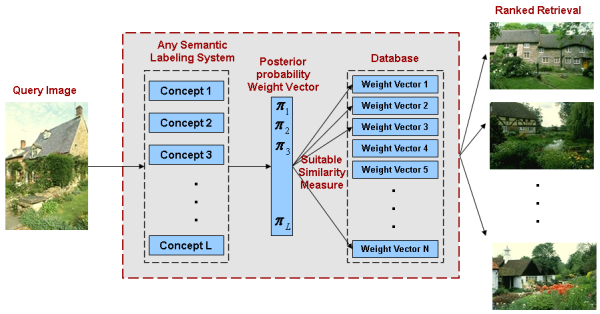
design systems that combine the benefits of the two classical paradigms. The
basic idea is to 1) define a semantic space , where each image is
represented by the vector of posterior concept probabilities assigned to it by
a semantic retrieval system, and 2) perform query-by-example in this space.
We refer to this combination as query-by-semantic-example (QBSE), and present an extensive comparison of its
performance with that of QBVE.
|
|
|
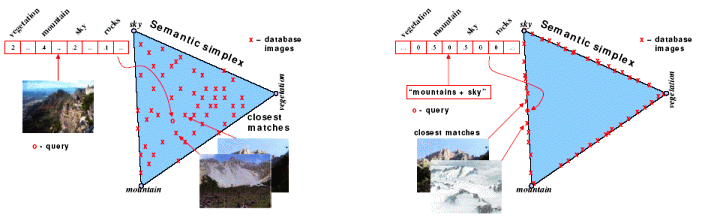
Semantic image retrieval. Left: Under QBSE the user provides a query image, probabilities are computed for all concepts, and the image represented by the concept probability distribution. Right: Under the traditional SR paradigm, the user specifies a short natural language description, and only a small number of concepts are assigned a non-zero posterior probability. |
| Demo |
On Corel dataset using 104 annotations |
| Results: |
Quantitative results (Perfomance measures) Some examples of image queries |
| Presentation: | Query by semantic example.ppt |
| Databases: |
We have used the following data-sets for image retrieval experiments. Please contact the respective people for information about obtaining the data:
|
| Publications: |
Bridging the Gap: Query by Semantic Example Rasiwasia, N., Moreno, P. L., Vasconcelos, N. Multimedia, IEEE Transactions on, Vol. 9(5), pp. 923-938, Aug 2007.© IEEE,[ps][pdf] |
| Query By Semantic Example Nikhil Rasiwasia, Nuno Vasconcelos, Pedro J Moreno Proceedings of the International Conference on Image and Video Retrieval LNCS 4071, pp. 51-60 Phoenix, Arizona, 2006. [ps][pdf] |
|
| Contact: | Nuno Vasconcelos, Nikhil Rasiwasia |
![]()
©
SVCL