SViTT: Temporal Learning of Sparse Video-Text Transformers
UC San Diego1, Intel Labs2
IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2023
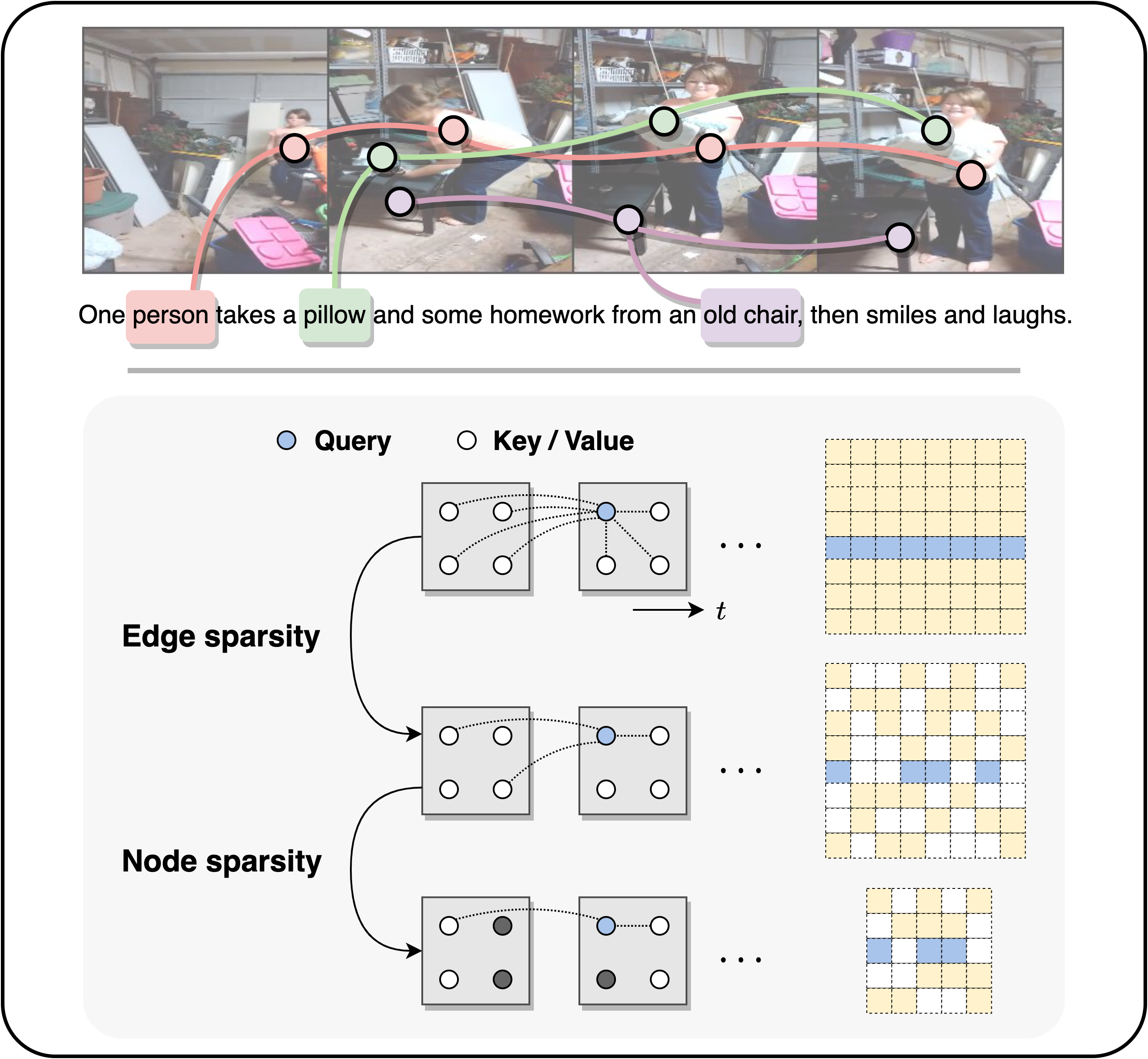
Overview
Do video-text transformers learn to model temporal relationships across frames? Despite their immense capacity and the abundance of multimodal training data, recent work has revealed the strong tendency of video-text models towards frame-based spatial representations, while temporal reasoning remains largely unsolved. In this work, we identify several key challenges in temporal learning of video-text transformers: the spatiotemporal trade-off from limited network size; the curse of dimensionality for multi-frame modeling; and the diminishing returns of semantic information by extending clip length. Guided by these findings, we propose SViTT, a sparse video-text architecture that performs multi-frame reasoning with significantly lower cost than naive transformers with dense attention. Analogous to graph-based networks, SViTT employs two forms of sparsity: edge sparsity that limits the query-key communications between tokens in self-attention, and node sparsity that discards uninformative visual tokens. Trained with a curriculum which increases model sparsity with the clip length, SViTT outperforms dense transformer baselines on multiple video-text retrieval and question answering benchmarks, with a fraction of computational cost.