Scaling up Recognition in Expert Domains with Crowd-source Annotations
Overview
The success of deep learning in image recognition is substantially driven by large-scale, well-curated data. On visual recognition of common objects, the data can be scalably annotated on online crowd-sourcing platforms because the labeling does not need any prior knowledge. However, the case is not true for images of expertise like biological or medical imaging in which labeling them needs background knowledge. Although data collection is still usually easy, the annotation is difficult. Existing self-supervised or semi-supervised solutions train a model that tries to learn from a small amount of labeled data and a large amount of unlabeled data. These solutions show good performances on common object recognition but have been found not to work effectively on fine-grained expert domains.
In this project, we propose a new solution with crowd source annotations to address the problem. Inspired by the fact that supervised learning on as much as data can always perform better, our method tries to scale up the annotation. This is implemented by machine teaching. Machine teaching first teaches humans with a short carefully designed course to learn the expertise knowledge so that they can label the data later. Beyond the approache, a unified explanation framework is developed to generate visualizations that are merged into the method, enabling easier and more accurate annotation results. Experiments show that the method significantly outperform various alternative approaches in several benchmarks. It has also been found to be versatile and can benefit from more advanced machine learning techniques in the future. Overall, we believe that this project opens up a new direction to think about the expert domain classification problem, in general.
Projects
A Machine Teaching Framework for Scalable Recognition
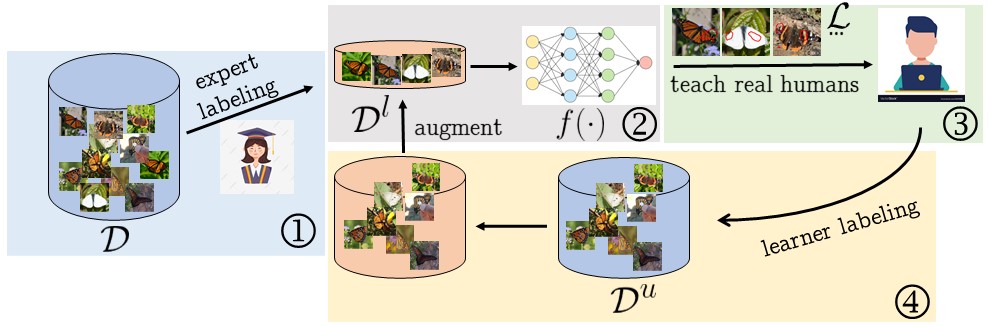
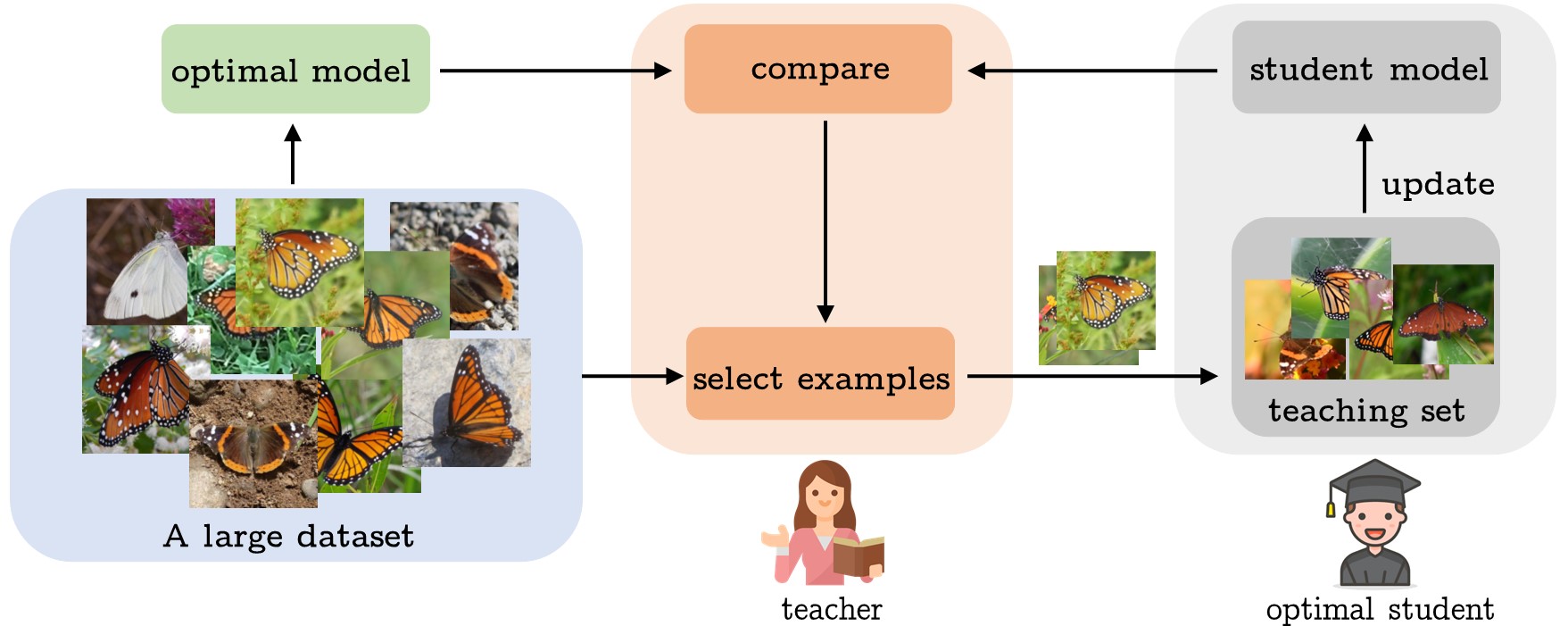
We consider the scalable recognition problem in the finegrained expert domain where large-scale data collection is easy whereas annotation is difficult. Existing solutions are typically based on semi-supervised or self-supervised learning. We propose an alternative new framework, MEMORABLE, based on machine teaching and online crowdsourcing platforms. A small amount of data is first labeled by experts and then used to teach online annotators for the classes of interest, who finally label the entire dataset. Preliminary studies show that the accuracy of classifiers trained on the final dataset is a function of the accuracy of the student annotators. A new machine teaching algorithm, CMaxGrad, is then proposed to enhance this accuracy by introducing explanations in a state-of-the-art machine teaching algorithm. For this, CMaxGrad leverages counterfactual explanations, which take into account student predictions, thereby proving feedback that is studentspecific, explicitly addresses the causes of student confusion, and adapts to the level of competence of the student. Experiments show that both MEMORABLE and CMaxGrad outperform existing solutions to their respective problems.
Gradient-Based Algorithms for Machine Teaching
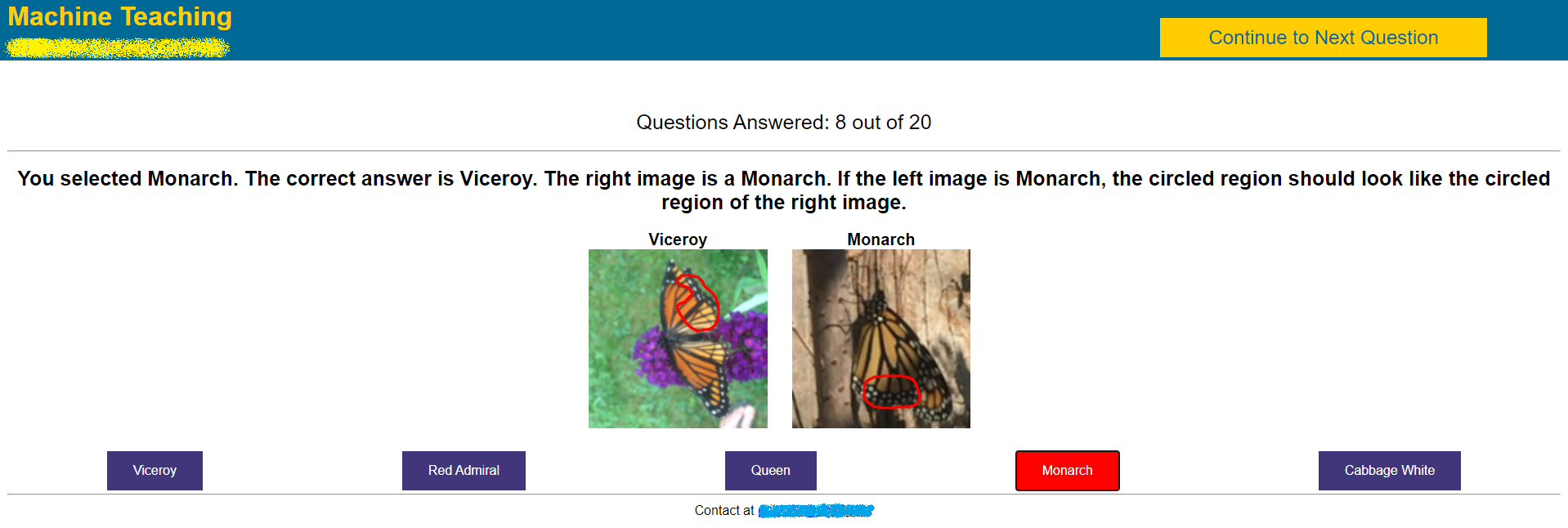
The problem of machine teaching is considered. A new formulation is proposed under the assumption of an optimal student, where optimality is defined in the usual machine learning sense of empirical risk minimization. This is a sensible assumption for machine learning students and for human students in crowdsourcing platforms, who tend to perform at least as well as machine learning systems. It is shown that, if allowed unbounded effort, the optimal student always learns the optimal predictor for a classification task. Hence, the role of the optimal teacher is to select the teaching set that minimizes student effort. This is formulated as a problem of functional optimization where, at each teaching iteration, the teacher seeks to align the steepest descent directions of the risk of (1) the teaching set and (2) entire example population. The optimal teacher, denoted MaxGrad, is then shown to maximize the gradient of the risk on the set of new examples selected per iteration. MaxGrad teaching algorithms are finally provided for both binary and multiclass tasks, and shown to have some similarities with boosting algorithms. Experimental evaluations demonstrate the effectiveness of MaxGrad, which outperforms previous algorithms on the classification task, for both machine learning and human students from MTurk, by a substantial margin.
SCOUT: Self-aware Discriminant Counterfactual Explanations
The problem of machine teaching is considered. A new formulation is proposed under the assumption of an optimal student, where optimality is defined in the usual machine learning sense of empirical risk minimization. This is a sensible assumption for machine learning students and for human students in crowdsourcing platforms, who tend to perform at least as well as machine learning systems. It is shown that, if allowed unbounded effort, the optimal student always learns the optimal predictor for a classification task. Hence, the role of the optimal teacher is to select the teaching set that minimizes student effort. This is formulated as a problem of functional optimization where, at each teaching iteration, the teacher seeks to align the steepest descent directions of the risk of (1) the teaching set and (2) entire example population. The optimal teacher, denoted MaxGrad, is then shown to maximize the gradient of the risk on the set of new examples selected per iteration. MaxGrad teaching algorithms are finally provided for both binary and multiclass tasks, and shown to have some similarities with boosting algorithms. Experimental evaluations demonstrate the effectiveness of MaxGrad, which outperforms previous algorithms on the classification task, for both machine learning and human students from MTurk, by a substantial margin.

Deliberative Explanations: visualizing network insecurities
A new approach to explainable AI, denoted deliberative explanations, is proposed. Deliberative explanations are a visualization technique that aims to go beyond the simple visualization of the image regions (or, more generally, input variables) responsible for a network prediction. Instead, they aim to expose the deliberations carried by the network to arrive at that prediction, by uncovering the insecurities of the network about the latter. The explanation consists of a list of insecurities, each composed of 1) an image region (more generally, a set of input variables), and 2) an ambiguity formed by the pair of classes responsible for the network uncertainty about the region. Since insecurity detection requires quantifying the difficulty of network predictions, deliberative explanations combine ideas from the literature on visual explanations and assessment of classification difficulty. More specifically, the proposed implementation combines attributions with respect to both class predictions and a difficulty score. An evaluation protocol that leverages object recognition (CUB200) and scene classification (ADE20K) datasets that combine part and attribute annotations is also introduced to evaluate the accuracy of deliberative explanations. Finally, an experimental evaluation shows that the most accurate explanations are achieved by combining non self-referential difficulty scores and second-order attributions. The resulting insecurities are shown to correlate with regions of attributes shared by different classes. Since these regions are also ambiguous for humans, deliberative explanations are intuitive, suggesting that the deliberative process of modern networks correlates with human reasoning.

Towards Realistic Predictors
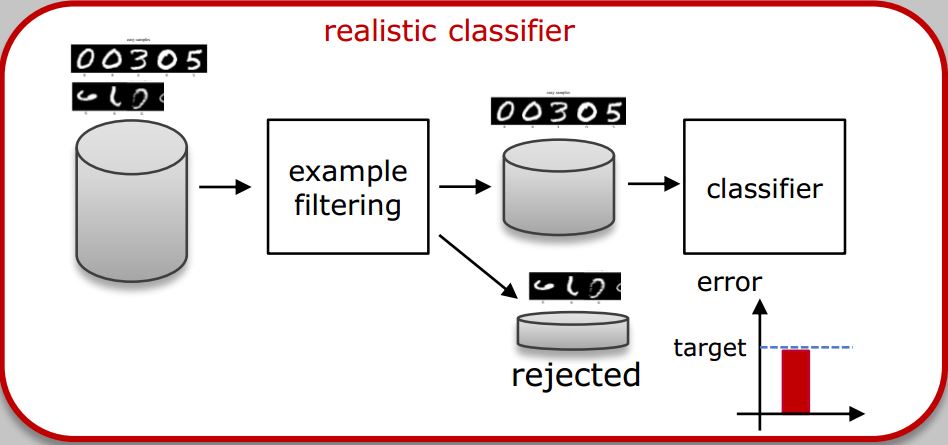
A new class of predictors, denoted realistic predictors, is defined. These are predictors that, like humans, assess the difficulty of examples, reject to work on those that are deemed too hard, but guarantee good performance on the ones they operate on. In this paper, we talk about a particular case of it, realistic classifiers. The central problem in realistic classification, the design of an inductive predictor of hardness scores, is considered. It is argued that this should be a predictor independent of the classifier itself, but tuned to it, and learned without explicit supervision, so as to learn from its mistakes. A new architecture is proposed to accomplish these goals by complementing the classifier with an auxiliary hardness prediction network (HP-Net). Sharing the same inputs as classifiers, the HP-Net outputs the hardness scores to be fed to the classifier as loss weights. Alternatively, the output of classifiers is also fed to HP-Net in a new defined loss, variant of cross entropy loss. The two networks are trained jointly in an adversarial way where, as the classifier learns to improve its predictions, the HP-Net refines its hardness scores. Given the learned hardness predictor, a simple implementation of realistic classifiers is proposed by rejecting examples with large scores. Experimental results not only provide evidence in support of the effectiveness of the proposed architecture and the learned hardness predictor, but also show that the realistic classifier always improves performance on the examples that it accepts to classify, performing better on these examples than an equivalent nonrealistic classifier. All of these make it possible for realistic classifiers to guarantee a good performance.
Publications
A Machine Teaching Framework for Scalable Recognition
Pei Wang, Nuno Vasconcelos
IEEE International Conference on Computer Vision (ICCV),
2021.
Gradient-Based Algorithms for Machine Teaching
Pei Wang, Kabir Nagrecha, Nuno Vasconcelos
IEEE Conference on Computer Vision and Pattern Recognition (CVPR),
2021.
SCOUT: Self-aware Discriminant Counterfactual Explanations
Pei Wang and Nuno Vasconcelos
IEEE Conference on Computer Vision and Pattern Recognition (CVPR),
2020.
Deliberative Explanations: visualizing network insecurities
Pei Wang and Nuno Vasconcelos
Conference on Neural Information Processing Systems (NeurIPS),
2019.
Towards Realistic Predictors
Pei Wang and Nuno Vasconcelos
European Conference on Computer Vision (ECCV),
2018.
Acknowledgements
This work was partially funded by NSF awards IIS-1924937, IIS-2041009, and gifts from NVIDIA, Amazon and Qualcomm. We also acknowledge and thank the use of the Nautilus platform for some of the experiments in the papers above.