YORO - Lightweight End to End Visual Grounding
UC San Diego
Overview
We present YORO - a multi-modal transformer encoder-only architecture for the Visual Grounding (VG) task. This task involves localizing, in an image, an object referred via natural language. Unlike the recent trend in the literature of using multi-stage approaches that sacrifice speed for accuracy, YORO seeks a better trade-off between speed an accuracy by embracing a single-stage design, without CNN backbone. YORO consumes natural language queries, image patches, and learnable detection tokens and predicts coordinates of the referred object, using a single transformer encoder. To assist the alignment between text and visual objects, a novel patch-text alignment loss is proposed. Extensive experiments are conducted on 5 different datasets with ablations on architecture design choices. YORO is shown to support real-time inference and outperform all approaches in this class (single-stage methods) by large margins. It is also the fastest VG model and achieves the best speed/accuracy trade-off in the literature

Published in European Conference On Computer Vision (ECCV) Workshop on International Challenge on Compositional and Multimodal Perception, Tel-Aviv, Israel, 2022.
Models
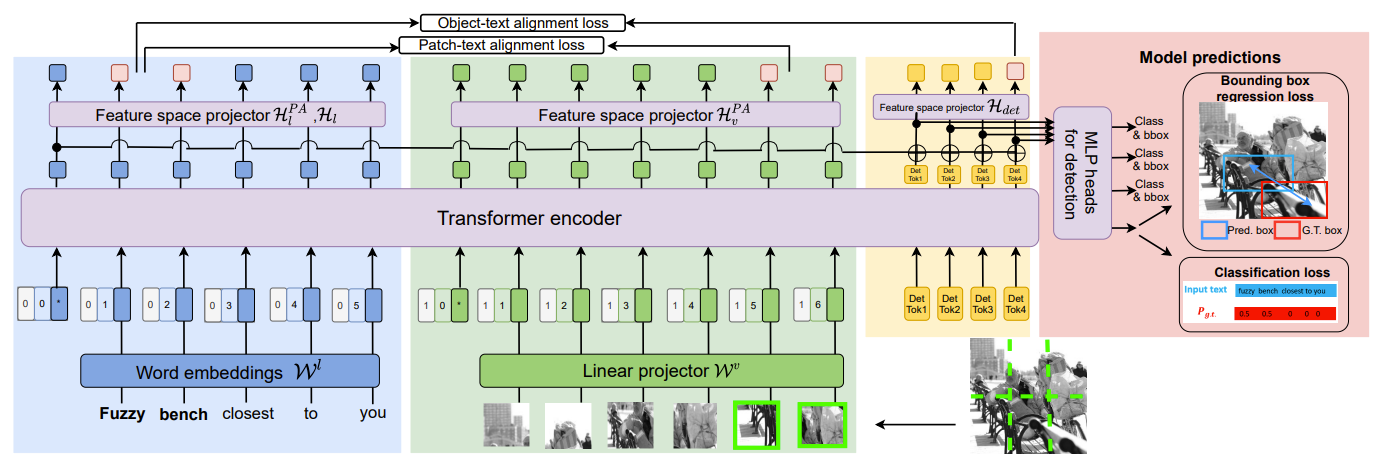
YORO Architecture: Blue, green, yellow and pink blocks represent language, vision, detection and prediction branches respectively. YORO does not use a large pre-trained visual backbone. Input image is divided into patches. Those of IOU > 0.5 with ground truth box (red) are marked in light green.
Code
Training, evaluation and deployment code available on GitHub.
Video

Acknowledgements
This work was partially funded by NSF awards IIS-1637941, IIS-1924937, and NVIDIA GPU donations.