Learning of Visual Relations: The Devil is in the Tails
UC San Diego1, Intel Labs2
(* indicates equal contributions)
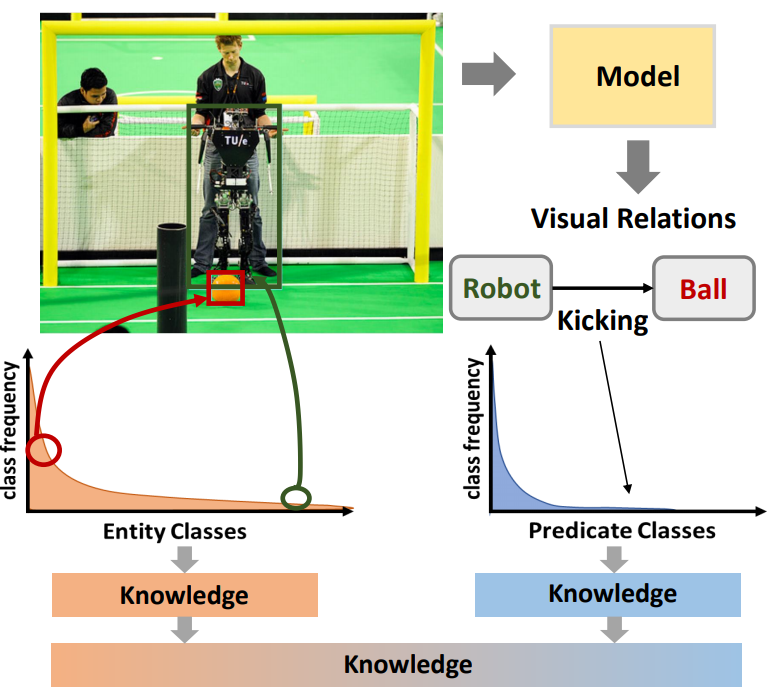
Overview
Significant effort has been recently devoted to modeling visual relations. This has mostly addressed the design of architectures, typically by adding parameters and increasing model complexity. However, visual relation learning is a long-tailed problem, due to the combinatorial nature of joint reasoning about groups of objects. Increasing model complexity is, in general, ill-suited for long-tailed problems due to their tendency to overfit. In this paper, we explore an alternative hypothesis, denoted the Devil is in the Tails. Under this hypothesis, better performance is achieved by keeping the model simple but improving its ability to cope with long-tailed distributions. To test this hypothesis, we devise a new approach for training visual relationships models, which is inspired by state-of-the-art long-tailed recognition literature. This is based on an iterative decoupled training scheme, denoted Decoupled Training for Devil in the Tails (DT2). DT2 employs a novel sampling approach, Alternating Class-Balanced Sampling (ACBS), to capture the interplay between the long-tailed entity and predicate distributions of visual relations. Results show that, with an extremely simple architecture, DT2-ACBS significantly outperforms much more complex state-of-the-art methods on scene graph generation tasks. This suggests that the development of sophisticated models must be considered in tandem with the long-tailed nature of the problem.

Published in IEEE International Conference on Computer Vision (ICCV), 2021.
Model

The architecture design of DT2 is simple, while the decoupled training scheme enables better feature and classifier learning for long-tailed visual relations.
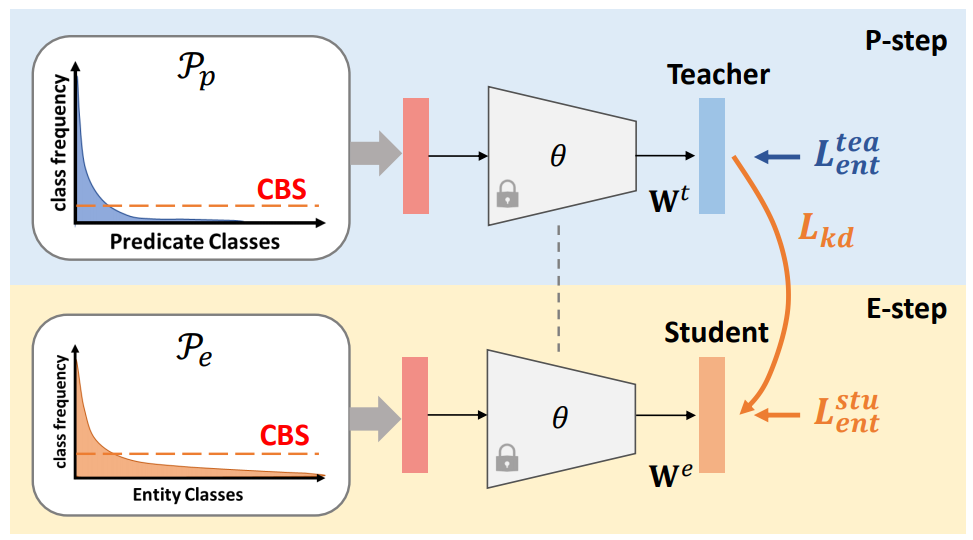
The proposed Alternating Class-Balanced Sampling (ACBS) captures the interplay between the long-tailed distributions of entities and relations by implementing the knowledge distillation between P-step and E-step.
Code
The code for training and evaluation and the model parameters will be available on GitHub (comming soon).
Results
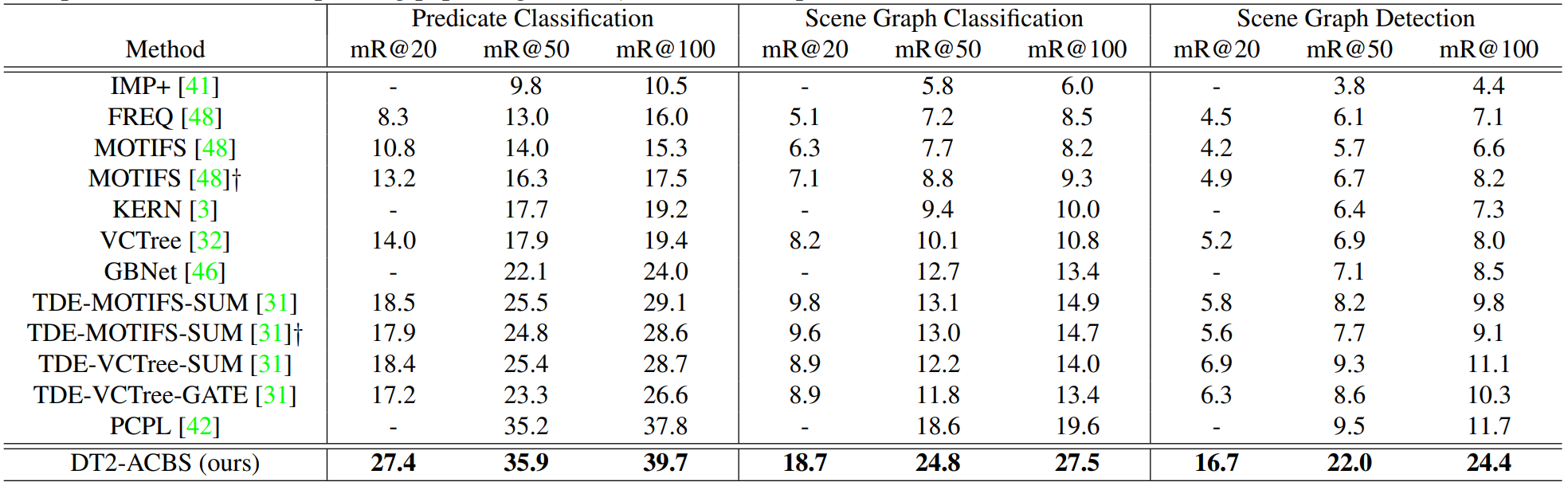
DT2-ACBS achieves STOA result on all SGG tasks with lower model complexity.

DT2-ACBS reaches the best balance across all classes.
Please refer to our paper for more ablations.
Visualization
In each sub-figure, colors of bounding boxes in the image (left) are corresponding to the entities in the triplets (upper-right) with the background color green/orange for correct/incorrect predicate predictions. In the generated graphs (lower-right), correct/incorrect predictions of entities and predicates are shown in purple/blue and green/orange respectively, with the ground truth noted in the bracket.
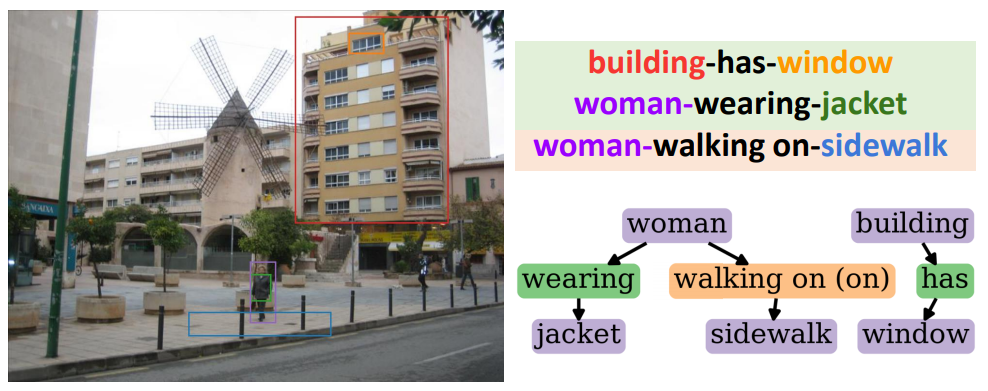




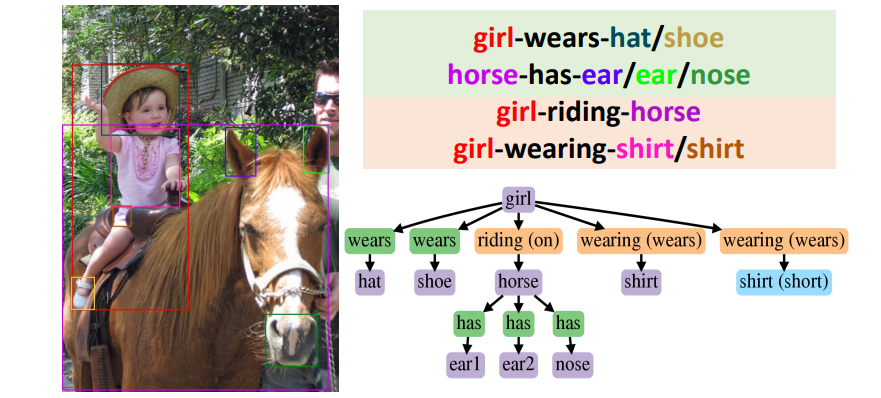
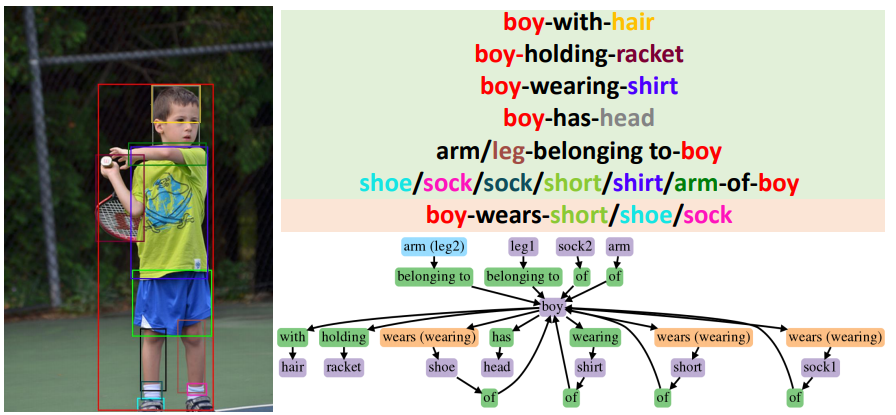
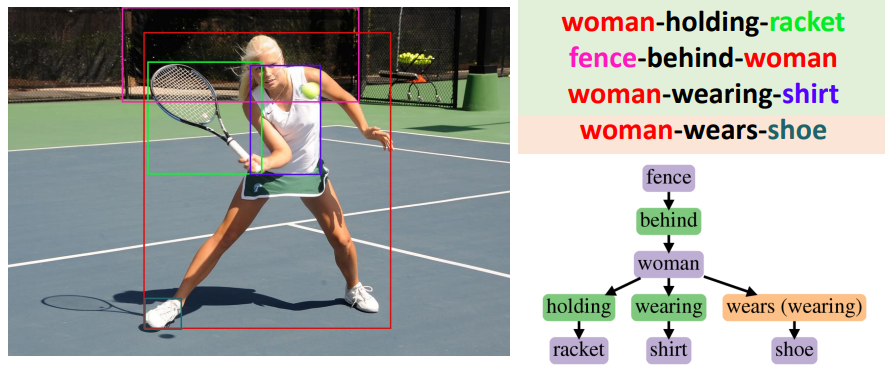
In PredCls task, DT2-ACBS can correctly predict populated predicate classes (has & wearing) as well as non-populated predicate classes (walking on). Not only robust to longtailed predicate classes, DT2-ACBS is also able to classify entities ranging from more populated classes (boy) to tail classes (sneaker).
Acknowledgements
This work was partially funded by NSF awards IIS-1924937, IIS-2041009 and a gift from Amazon.