![]()
| Home | People | Research | Publications | Demos |
| News | Jobs |
Prospective
Students |
About | Internal |

Visual Undesrtanting of Complex Human Behavior
via Attribute Dynamics
|
|
Understanding human behavior has been a fundamental topic ever since the inception of machine vision. This work is part of our efforts in video analysis and semantic understanding of media data, with focus on video events that consist of compelx human behavior in open source sequences. Being one of the toughest tasks in computer vision, major challenges of this problem include: 1) sophisticated storyline, event composition of long video sequences; 2) significant intra-class variation due to sparse examplification, highly variable sequencing of complex events; 3) ubiquitous ambiguities caused by scattered visual and semantic noise.
A very pupular solution to video understanding relies on bag-of-visual-words (BoVW) representation, which characterizes a viedo by an orderless collection of local features and uses a vector aggregated from these features to represent the whole visual example. Despite its significant popularity and success in recognition, BoVW fails to account for two critical properties for video understanding:
To address the aforementioned limitations of the popular BoVW representaion, two major extensions were proposed in the vision literature. In the first dimension, given the significance of temporal structure in video understanding, people model the evolution patterns of human behavior on top of low-level representations, which is typically implemented with parametric models such as dynamic Bayesian networks. This frequently relies on either complicated pre-processing components (e.g., detection and tracking of human bodies), or representations prone to noise (e.g., pixel-level visual signal). In result, doing so is difficult to generalize to many realistic scanarios in open-source videos. On the other hand, attribute-based visual representation also became popular for their appealing properties in generalization. These two directions, however, only address the limitation from one sole perspective.
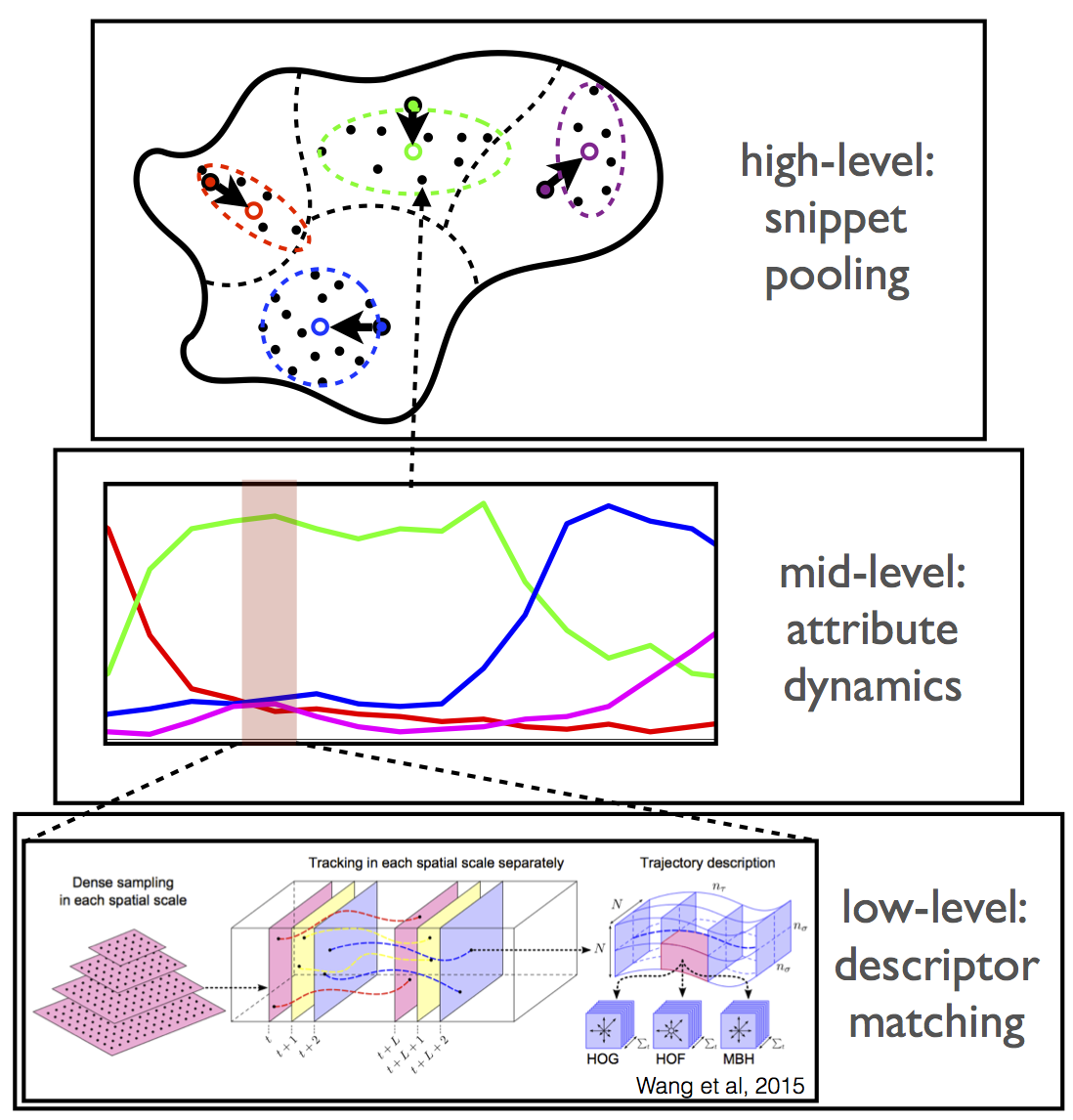
In this work, we aim to combine the benefits of both by modeling temporal structure of human bahavior on top of attribute represenation, which is denoted attribute dynamics. Overall, this work has three major contributions: 1) On the conceptual level, we propose attribute dynamics to characterizing human activity, which is integrated as a mid level represenation in a hierarchy that depicts a complex video event via three layers with each layer encoding the event at a specific temporal/semantic granularity. It is shown that, attribute dynamics can capture consistent complex human motion patterns relibaly and provides a semantic understanding platform that facilitates several video applications (e.g., recognition, recounting, retrieval). 2) We developed a principled framework of technical solutions to working with attribute dynamics. These include the binary dynamic system (BDS) and its mixture model for attribue dynamics encoding, BDS learning and inference via variational methods, probabilistic kernels via BDS for example discrimination, bag-of-model clustring for BDS codebook learning, Fisher vectors for example encoding, etc. 3) For practical application, we show that conventioanl tasks of video analysis can benefit from reasoning with the temporal structrue of human behavior in the attribute space. As the result, our solution produces state-of-the-art performance on several action recognition benchmarks, enables target-driven event recounting, and story-based semantic video retrieval.
| To cope with its distinct proterties at different temproal scales, we represent complex events with a hierarchy that breaks an event into three levels of temporal/semantic granularities, and tailor specific strategies to address challenges at different levels. Low-level motion: Action at this level are typically short-term instantaneous motion. Conventional methods such as BoVW are applied to model this type of movement. Mid-level dynamics: Activity at this level typically exhibits constinuous evolution patterns, as it is mostly driven by social convention, recipes, protocols, etc. Modeling this consistent transition dynamics in the attribute space provides robust encoding of mide-level activities, and facilitates semantic reasoning. High-level event: Due to highly variable compostion, instances of a complex event are subject to significant inhomogeneity. This often breaks the continuity of an event's global temporal structure. On the other hand, local event evidences are more reliable to infer the original story. |
|
|
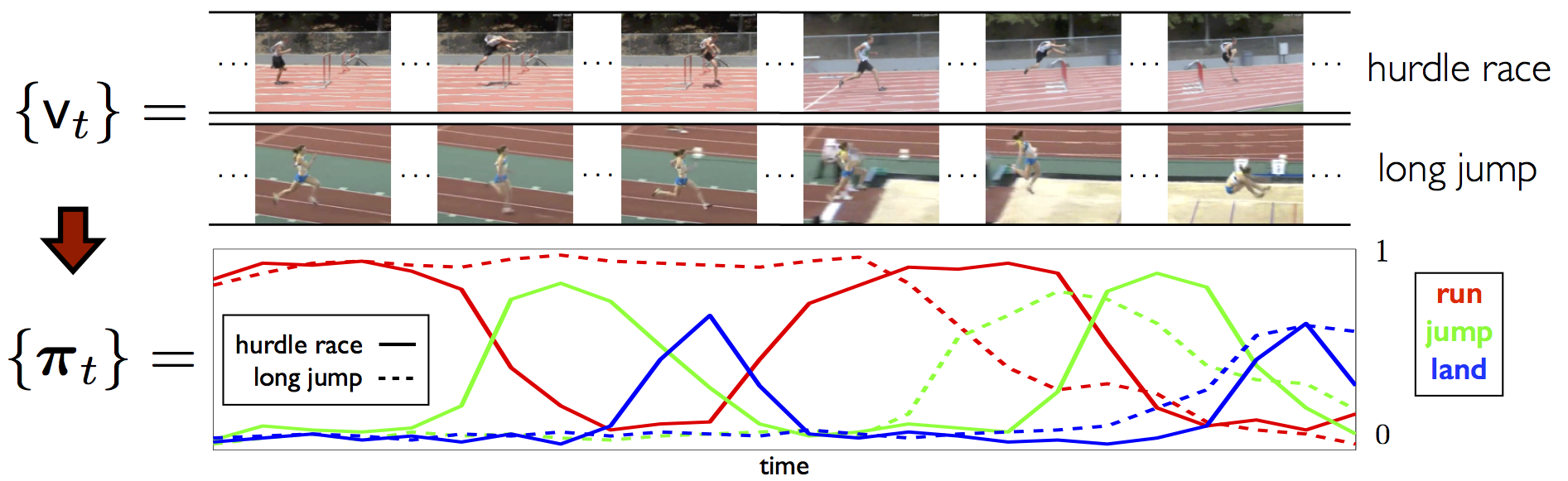
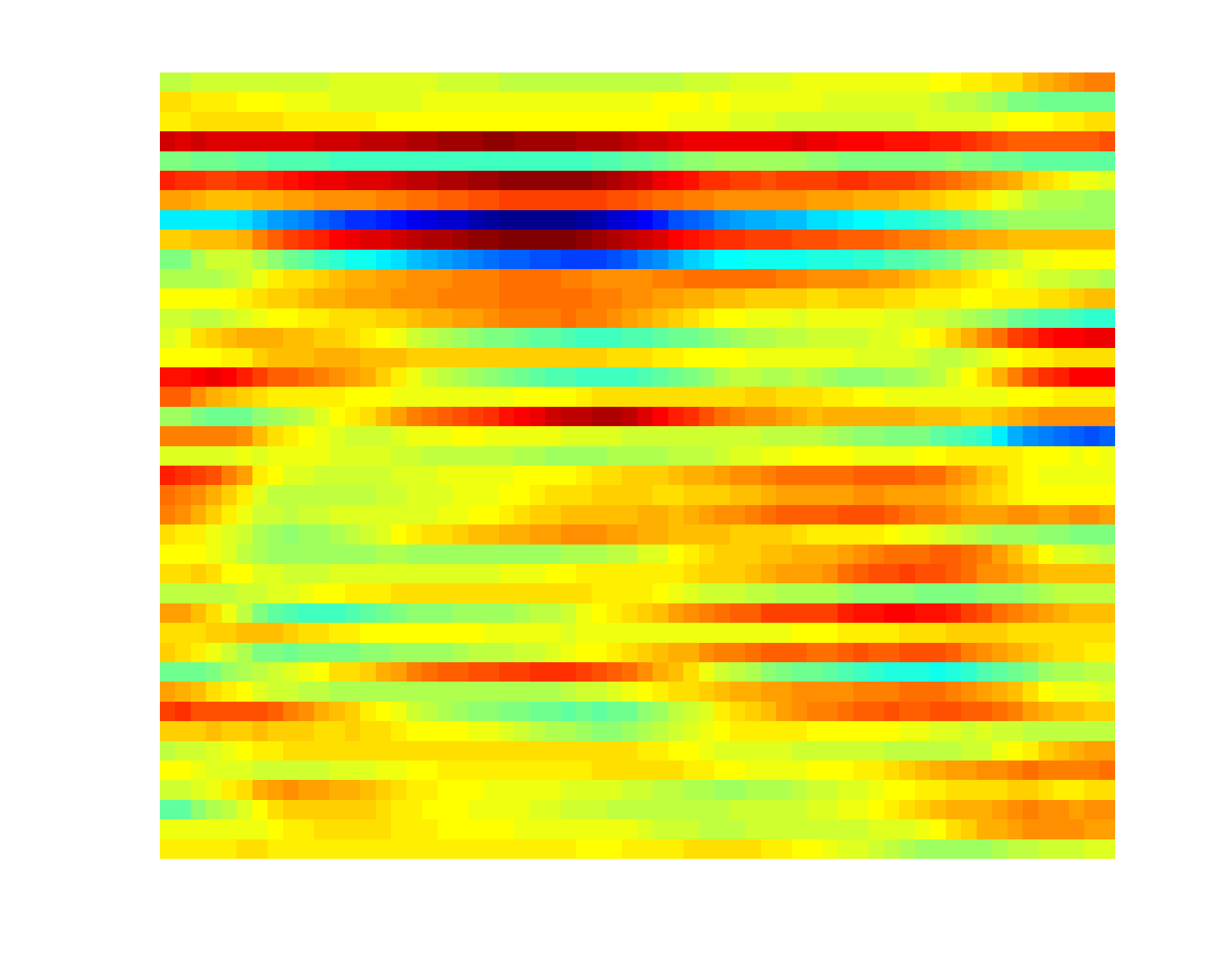
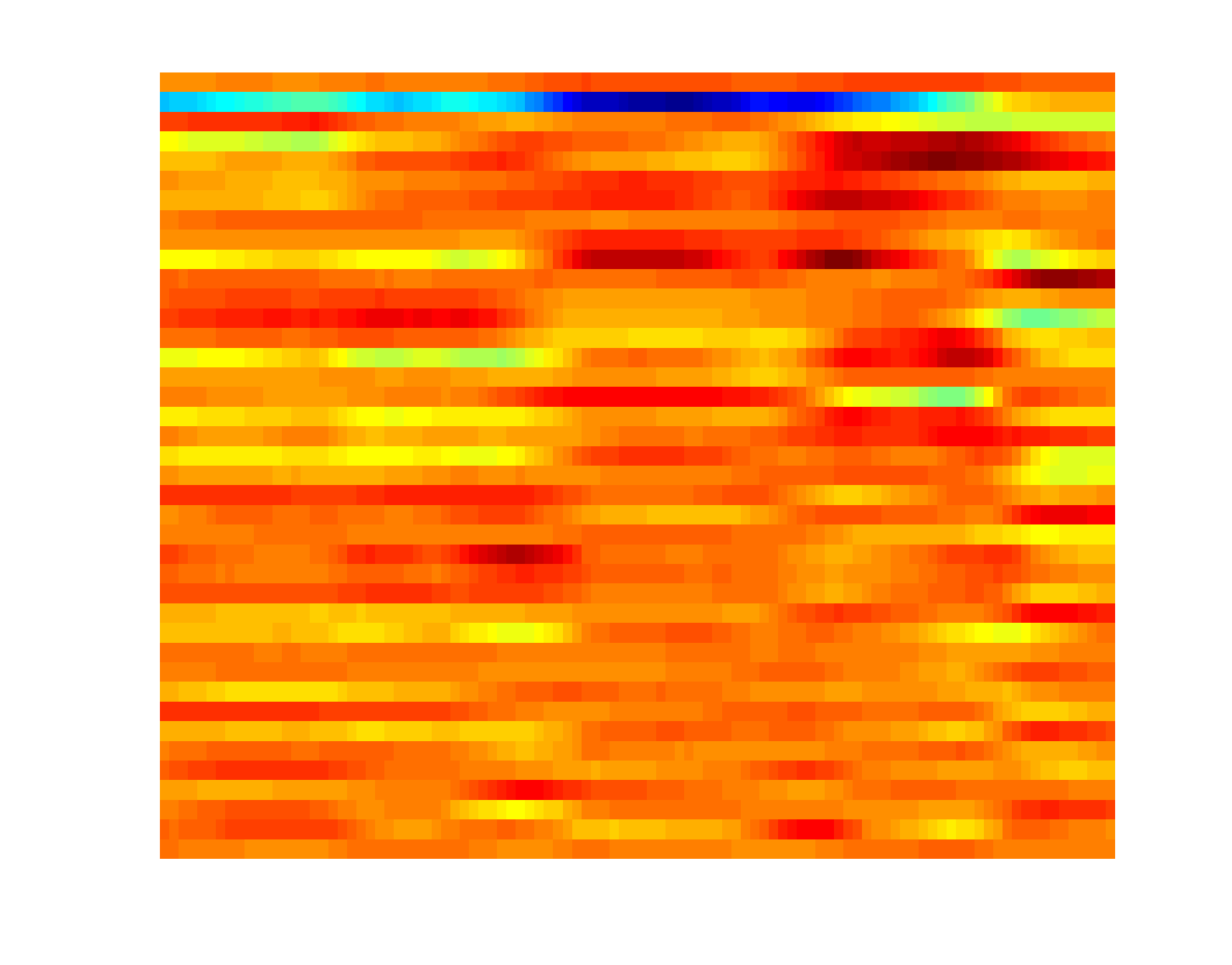
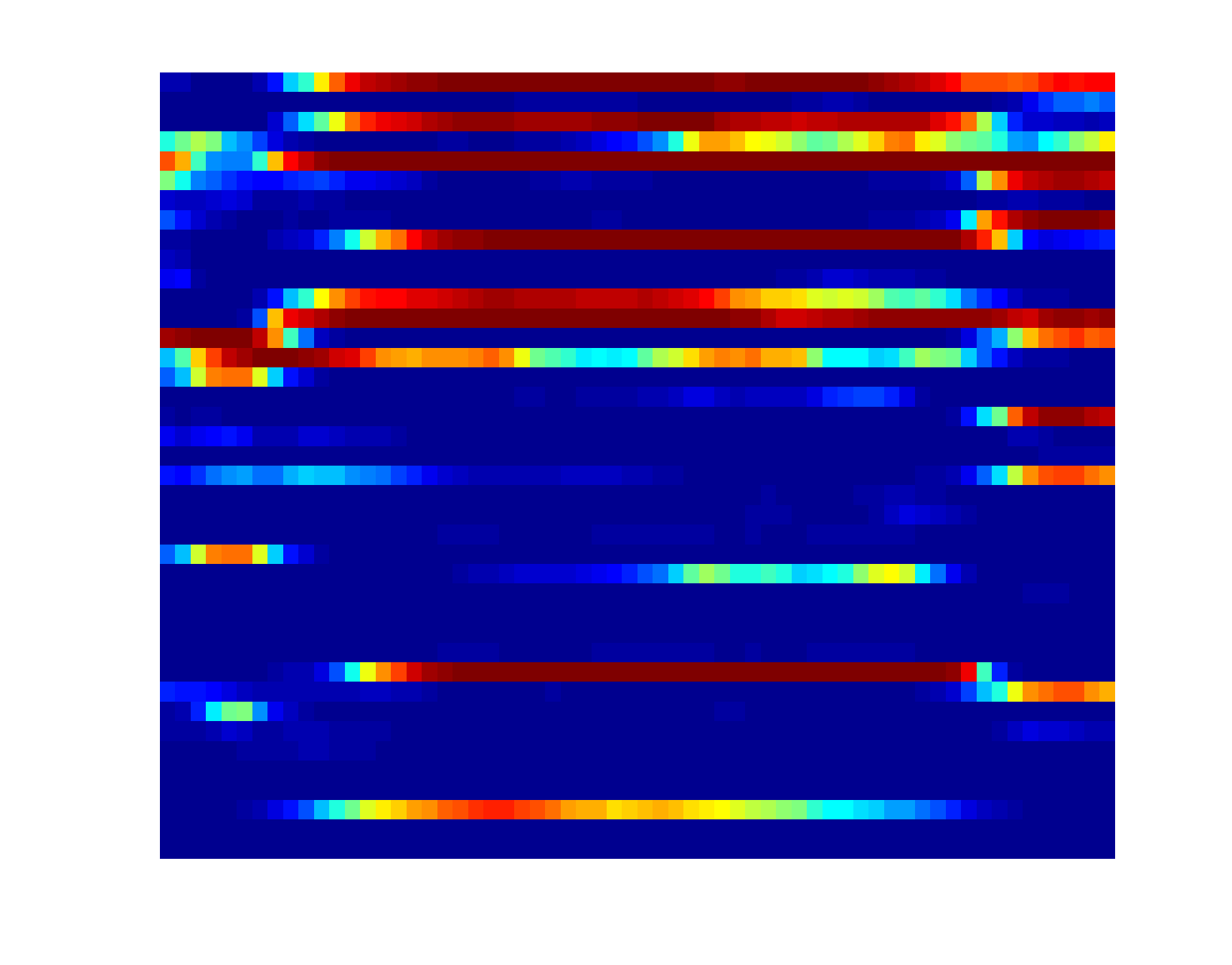
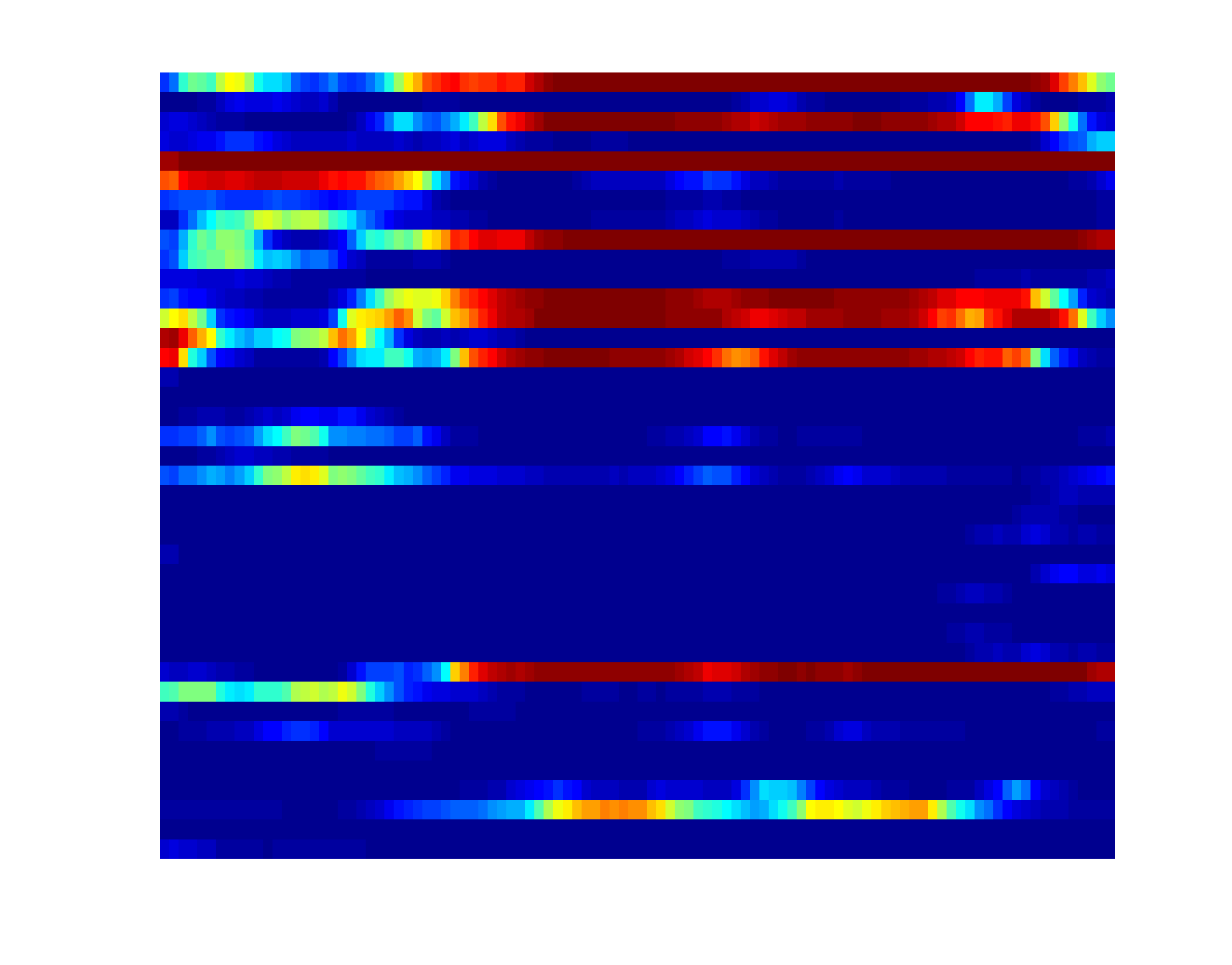
Attribute-based representation brings in a robust and seamntically meaningful intermediate layer between low-level visual signals and high-level concepts for many vision problems (image, video, etc). For video, three types of attributes are widely used, including atomic action, backgroung scene and object. Presence of each of these attributes can be quantified by the corresponding detector, which is an active research area in computer vision. A K-d attribute sequence can be produced if K attribute detectors are applied to the key frames of a video. Modeling the evolution pattern in this sequence ("attribute dynamics") reveals the intrinsic story of the video sequence. Attribute dynamics provides a more relibale and consistent description of temporal structure in a video than the evolution pattern in low-level visual signals (e.g. BoVW). To see this, three instances of triple-jump are shown below, where both the attribute and BoVW representation at each key frame of the video are plotted over time (horizontal axis). |
|
||||||||||||||||||
| video sequence for "Triple Jump" | |||
|
BoVW sequence (projected to 40-d PCA space) |
|
|
|
|
Attribute sequence (40 attributes) |

time |
time |
time |
| To model the attribute dyanimcs of a multi-dimentional binary attribute sequnece, a novel dynamic Bayesian network, bianry dynamic system (BDS), is proposed. A generalization of the canonical linear dynamic system (LDS) to account for biarny data, BDS consists of two comoponents: 1) dynamic component, a first-order Gauss-Markov process to encode the evolution of hidden states; and 2) observation component, a multi-variate Bernoulli distribution with natural parameters linear projected from the hidden states. Since the Gaussian hidden state is not a conjugate prior to the Bernoulli observation, exact statistical inference is intractable in BDS. In this work, we resort to variational methods for approximate inference and parameter estimiation. It has been shown that, with a tight lower-bound for the log-evidence inspired by the Bayesian logistic regression, our solution achieves good performance in both accurarcy and efficiency. |
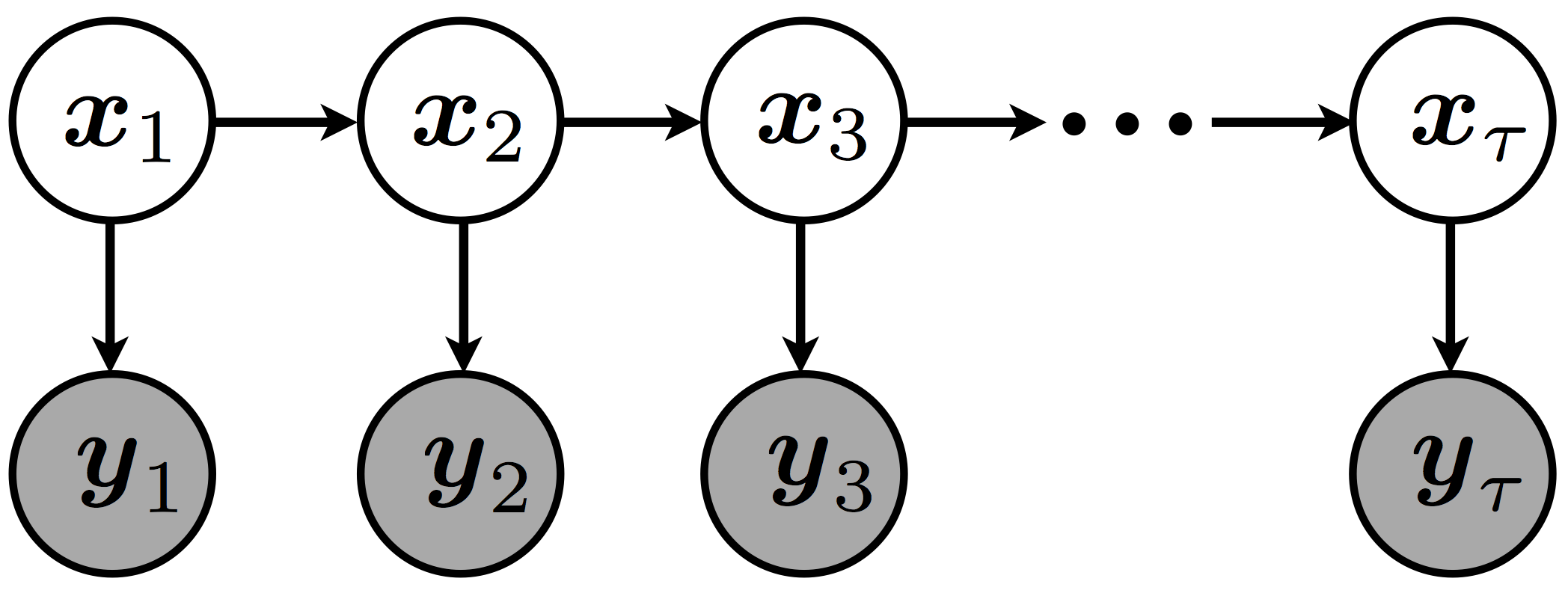
|
Recognizing a high-level event in a compelx video requires properly encoding the critical content from the long sequence since 1) the global temporal structure of the long sequence is typically not informative of the high-level event, and 2) most events can be inferred from signature snippets. In this work, we propose to encode a long complex event by the contents of its local events via a divide-and-conquer strategy: 1) a long sequence is first split into multiple snippets; 2) each local event in a snippet is explained by a BDS; and 3) the holistic video is represented by aggregating information from these BDS's. In this way, a BDS only needs to focus on modeling the local evolution pattern of a mid-level activity in a snippet, and the highly variable global holistic temporal strucutre is disregarded for robustness.
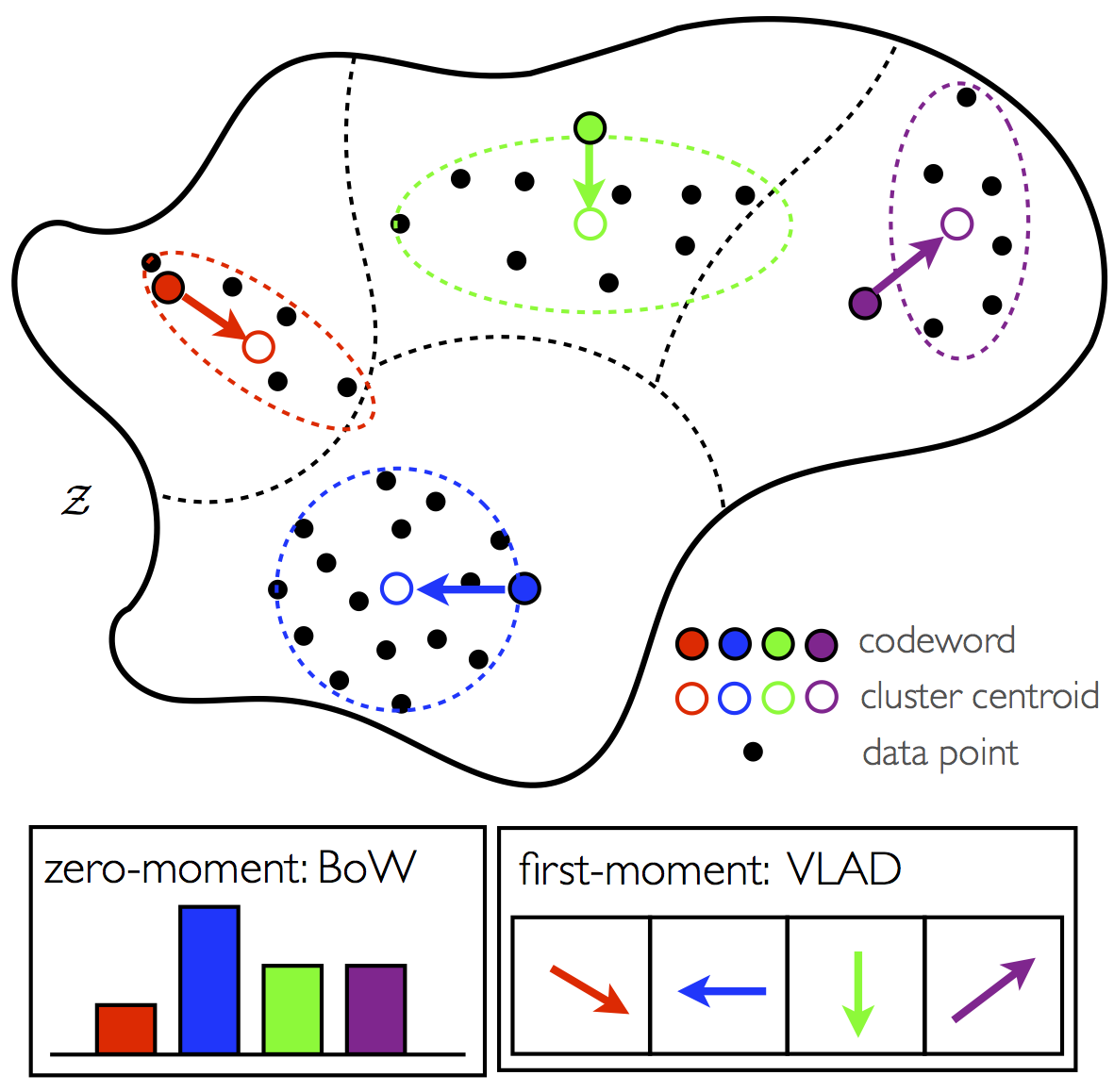
The aggregation of information from local eveidence is implemented by computing the statistics of local attribute sequences in snippets via a pre-learnt codebook of BDS's. Two methods are proposed to encode the zeroth and first moments of attribute sequences.
Zeroth-moment: Bag-of-Words for Attribute Dynamics (BoWAD)The zeroth moment comptutes the counts of codewords that explain the attribute sequences in snippets: each attribute sequence is assigned to a BDS codeword that best expalins it; the histogram of these BDS codewords is used to represent the whole complex event. First-Moment: Vector of Locally Aggregated Descriptors for Attribute Dynamics (VLADAD)The first moment encodes the position of the centroid of examples assigned to a BDS codeword: Each attribute sequence is first assigned to a BDS codeword that best expalins it; for all exmaples assigned to a particular BDS, the position of their centroid relative to the BDS is used to encode the example cloud; these centroid positions relative to all BDS codewords are concatenated to summarize the local events of the whole complex sequence. |
|
Our hierarchical representation for complex events has several interesting connections to the popular deep networks. In the big picture, both architerctures share similar hierarchy formulation with different flavors for each layer: 1) at the low-level, ours adopts the visual word quantization for matching, while deep networks utilize template convolution; 2) for mid-level semantics, we enforce explicit suptervised attributes while deep networks learn the implicit concepts without supervision; 3) at the high-level representation, statistics of evolution patterns from local evidence is computed to represent complex events, while deep networks rely on pooling schemes to construct the representation. These distinction leads to difference in learning as the result: our framework requries supversion at each layer of the hierarchy (e.g., hand-crafted low-level features, mid-level attribute definition, and high-level event labeling), which deep networks only need supersion at the very top layer, which enables the end-to-end training.
In fact, these connections suggest that our framework can incorporate the componets from deep networks for convinience. For instance, in one of our latest work, when combined with the state-of-the-art deep networks for low-level visual representation, VLADAD achieves the state-of-the-art performance on several benchmarks for action recognition.
Using the BoWAD and VLADAD, action & event recognition can be performed efficiently with many types of classification schemes, e.g., support vector machines (SVMs). This has outperformed previous state-of-the-art approaches modeling video temporal structure on several benchmarks, e,g,, Olympic Sports, TRECVID multimedia event detection (MED).
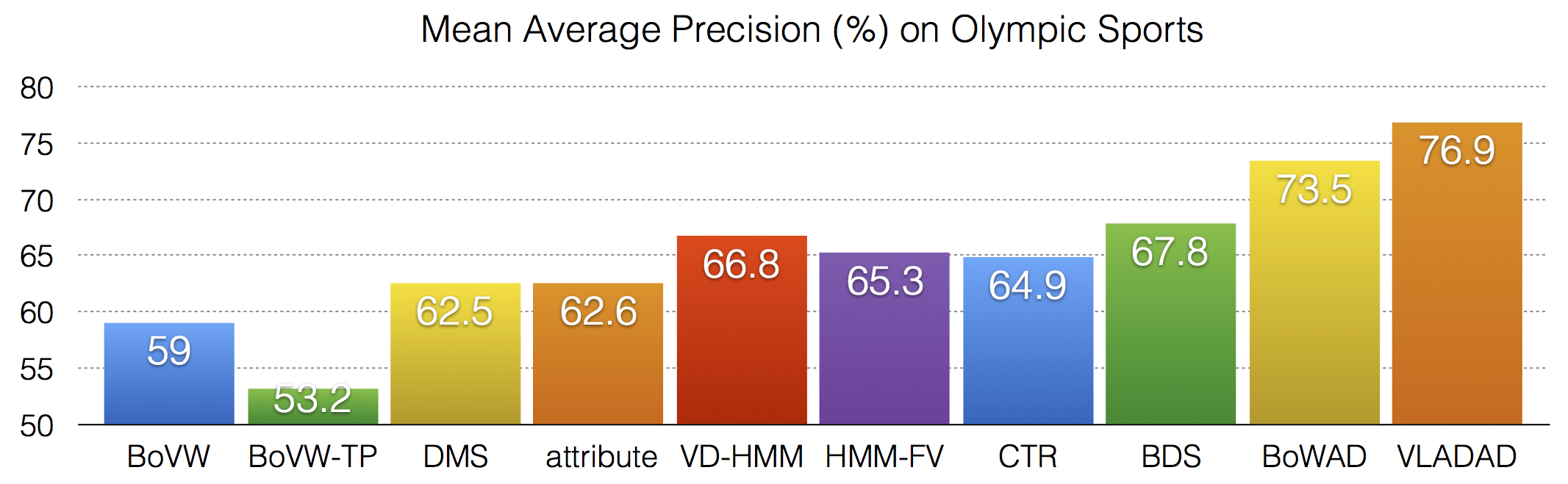
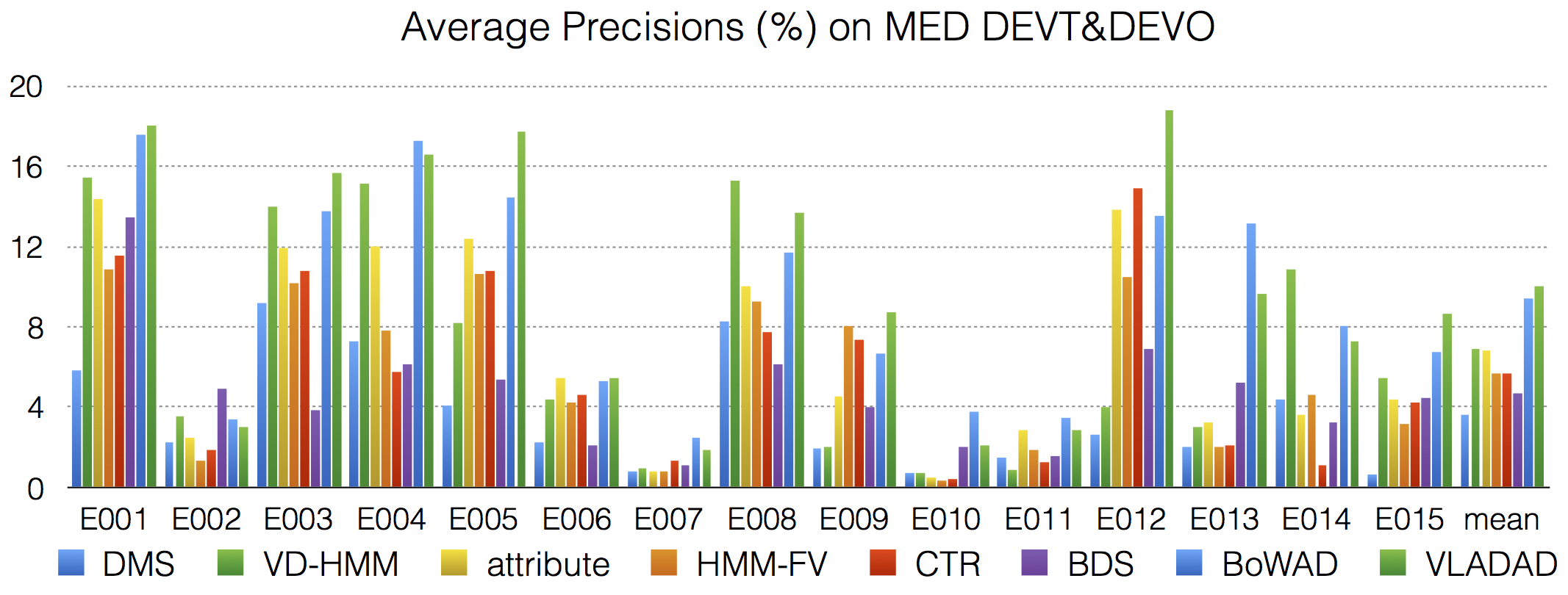
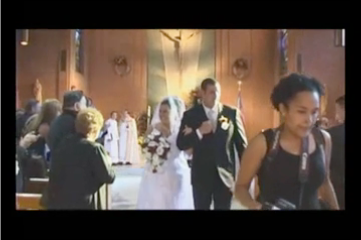
One appealing application of the BoWAD/VLADAD is the content-based video recounting. Conventional action & event recognition approaches only provide final prediction, while it is more desirable, from the perspective of media data analysis, to show the evidence based on which the prediction is made. This can be naturally implemented with BoWAD/VLADAD and enables semantic segmentation & summarization of video sequences. Examples of recounting for complex event "wedding ceremony" and "change type" with BoWAD are shown below. See here for the video snapshots.


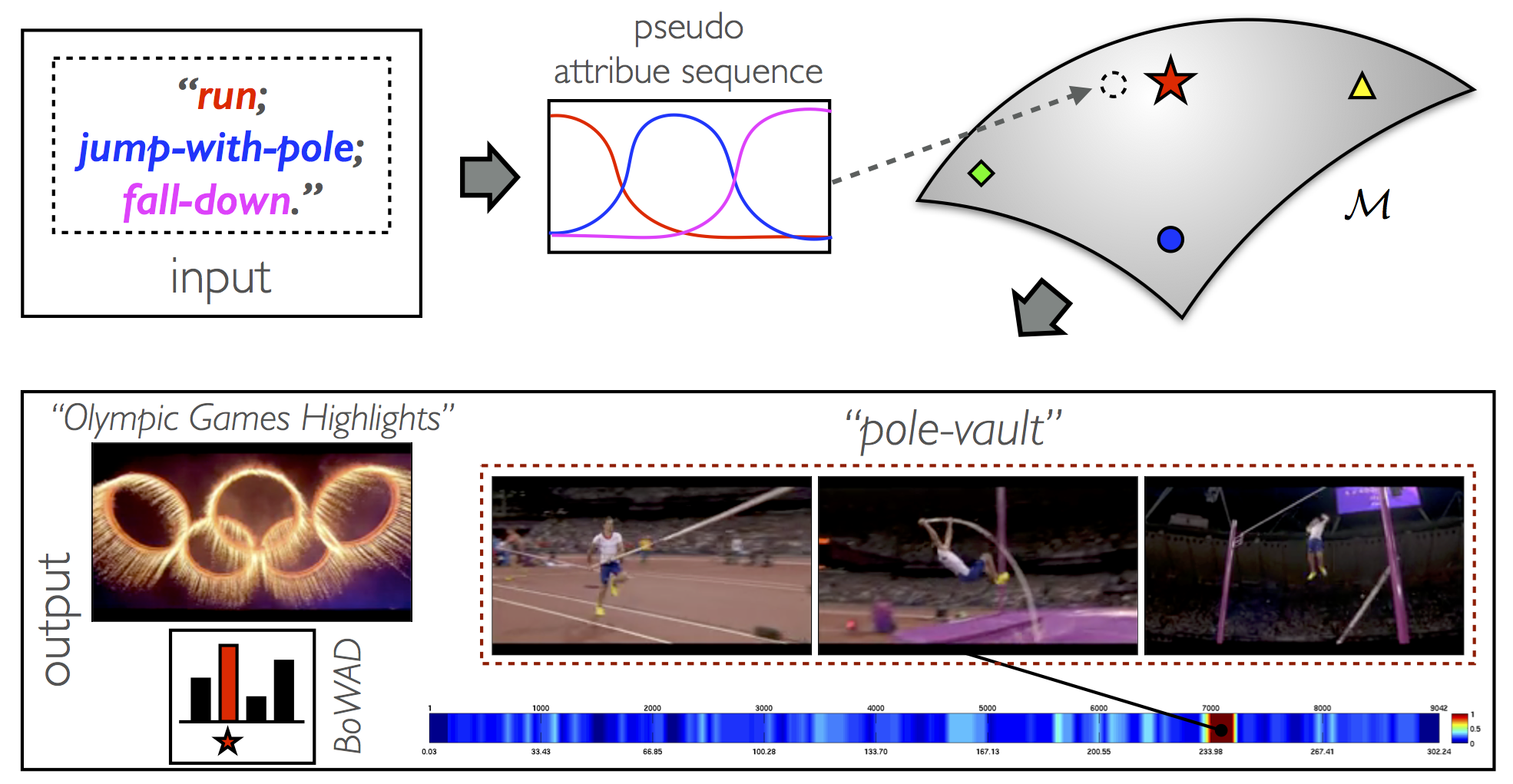
Another application of semantic reasoning with BoWAD/VLADAD is the semantic retrieval of video data. One way of doing so is that a query video sequence provided by a user is first represented by either BoWAD/VLADAD, and then video sequences in the databsae those BoWAD/VLADAD are most similar to that of the query example are returned as the result. Another possibility is that an user can even provide a virtual sequence of attribute description of the desired video content, e.g., "an athlete runs, jumps with a pole, and falls down", and then the video sequence "Olympic Games Highlights" in the database with a snippet "pole vault" whose associated BDS can explain the query sequential attribtue description is returned as the result. See here for the whole video snapshots.
Visual Understanding of Complex Human Behavior via Attribute Dynamics
Wei-Xin LI
Ph.D. Dissertation, UC San Diego, 2016
[
pdf |
BibTeX
]
Complex Activity Recognition via Attribute Dynamics
Wei-Xin LI
and
Nuno Vasconcelos
International Journal of Computer Vision (IJCV)
to appear in the printed version,
available
online on June 21, 2016
[
preprint (pdf) |
DOI |
BibTeX
]
VLAD3: Encoding Dynamics of Deep Features for Action Recognition
Yingwei Li,
Wei-Xin LI,
Vijay Mahadevan
and
Nuno Vasconcelos
Proc. of
IEEE Conf. on Computer Vision and Pattern Recognition (CVPR)
Las Vegas, Nevada, United States, 2016
[
pdf |
DOI |
BibTeX
]
Recognizing Activities via Bag of Words for Attribute Dynamics
Wei-Xin LI,
Qian Yu,
Harpreet Sawhney
and
Nuno Vasconcelos
Proc. of
IEEE Conf. on Computer Vision and Pattern Recognition (CVPR)
Portland, Oregon, United States, 2013
[
pdf |
DOI |
BibTeX ]
Recognizing Activities by Attribute Dynamics
Wei-Xin LI
and
Nuno Vasconcelos
Advances in
Neural Information Processing Systems (NIPS)
Lake Tahoe, Nevada, United States, 2012
[
pdf |
BibTeX ]
![]()
©
SVCL