Toward Unsupervised Realistic Visual Question Answering
UC San Diego

Examples of CLIP based (a,b,e,f) and Perturbation (PT) based UQs (c,d,g,h) in RGQA. For the PT-based UQs, the red words are modified from the original question.
Overview
The problem of realistic VQA (RVQA), where a model has to reject unanswerable questions (UQs) and answer answerable ones (AQs), is studied. We first point out 2 drawbacks in current RVQA research, where (1) datasets contain too many unchallenging UQs and (2) a large number of annotated UQs are required for training. To resolve the first drawback, we propose a new testing dataset, RGQA, which combines AQs from an existing VQA dataset with around 29K human-annotated UQs. These UQs consist of both fine-grained and coarse-grained image-question pairs generated with 2 approaches: CLIP-based and Perturbation-based. To address the second drawback, we introduce an unsupervised training approach. This combines pseudo UQs obtained by randomly pairing images and questions, with an RoI Mixup procedure to generate more fine-grained pseudo UQs, and model ensembling to regularize model confidence. Experiments show that using pseudo UQs significantly outperforms RVQA baselines. RoI Mixup and model ensembling further increase the gain. Finally, human evaluation reveals a performance gap between humans and models, showing that more RVQA research is needed.

Published in International Conference on Computer Vision (ICCV), 2023.
Models
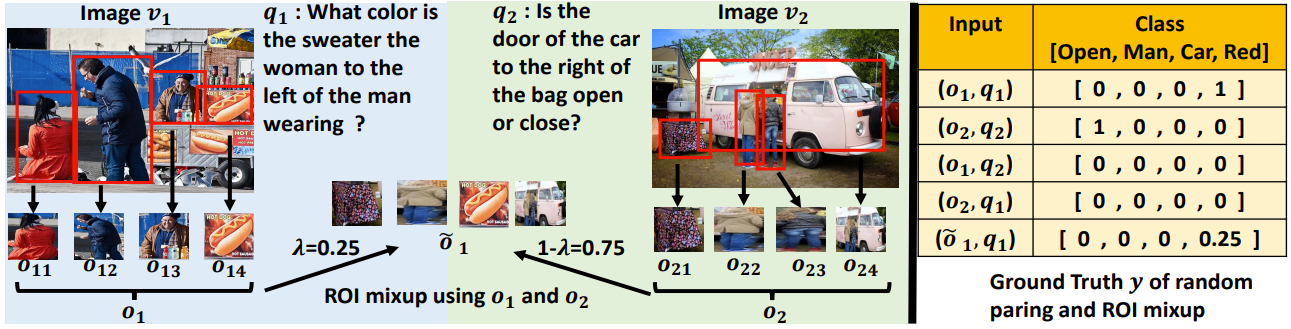
Illustration of the pseudo UQ and RoI Mixup. The right table shows the label for different visual question inputs
Code
Training, evaluation and deployment code available on GitHub.
Video

Acknowledgements
This work was partially funded by NSF awards IIS-1637941, IIS-1924937, and NVIDIA GPU donations.