![]()
| Home | People | Research | Publications | Demos |
| News | Jobs |
Prospective
Students |
About | Internal |

| Regularization on Content-based Image Retrieval | ||
|
In query-by-semantic-example image retrieval, images are ranked by similarity of semantic descriptors, or semantic multinomials (SMN). These descriptors are obtained by classifying each image with respect to a pre-defined vocabulary of semantic concepts as is shown in the picture below for a simple vocabulary of 3 concepts ('chairs', 'animals' and 'vehicles'). This abstract space representation of visual data is more aligned with human visual recognition, and therefore tends to have better results in classical vision problems such as content-based image retrieval (CBIR). It is well known that existing low-level representations of images do not encode human notion of similarity. This is the so-called semantic gap problem that has been extensively studied. |
||

|
||
|
From previous studies on cross-modal retrieval, it is also well known that for a test sample based on a collection of text and images, the task of retrieving texts based on query images, attains better retrieval performance than the converse task. Not surprisingly, this leads to the belief that texts contain more useful semantic information, that aids on retrieval based on semantic descriptors. |
||
 |
||
|
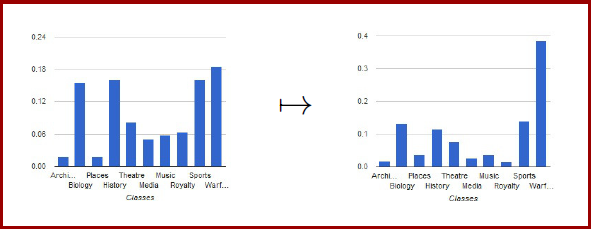
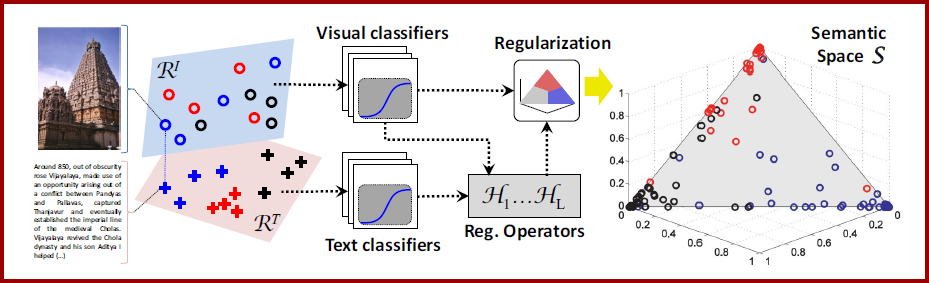
In this work, we consider the problem of improving the accuracy of semantic descriptors through cross-modal regularization, based on auxiliary text. A cross-modal regularizer, composed of three steps, is proposed. Training images and text are first mapped to a common semantic space. A regularization operator is then learned for each concept in the semantic vocabulary. An overview is provided in the figure below. |
 |
|
|
||
|
The learned regularization operators map the semantic descriptors of images to the descriptors of the associated texts. A convex formulation of the learning problem is introduced, enabling the efficient computation of concept-specific regularization operators. The third step is the selection of the most suitable operator for the image to regularize. This is implemented through a quantization of the semantic space, where a regularization operator is associated with each quantization cell. Overall, the proposed regularizer is a non-linear mapping, implemented as a piecewise linear transformation of the semantic image descriptors to regularize. This transformation is a form of cross-modal domain adaptation. It is shown to achieve better performance than recent proposals in the domain adaptation literature, while requiring much simpler optimization. |
||
| Code: |
Please check links under the Publications section below. |
| Publications: |
Cross-modal Domain Adaptation for Text-based Regularization of Image Semantics in Image Retrieval Systems
J. Costa Pereira and N. Vasconcelos Computer Vision and Image Understanding Vol. 124, pp. 123-135, July 2014 © Elsevier [ps] [pdf] [BibTeX] |
|
On the Regularization of Image Semantics by Modal Expansion
J. Costa Pereira and N. Vasconcelos In proceedings of IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Providence, Rhode Island, USA - Jun. 2012 © IEEE [ps] [pdf] [BibTeX] [code] [online demo] |
|
| Contact: | Jose Costa Pereira, Nuno Vasconcelos |
![]()
©
SVCL