
| Home | People | Research | Publications | Demos |
| News | Jobs |
Prospective Students |
About | Internal |

| Holistic Context Models for Visual Recognition. | |
|
|
|
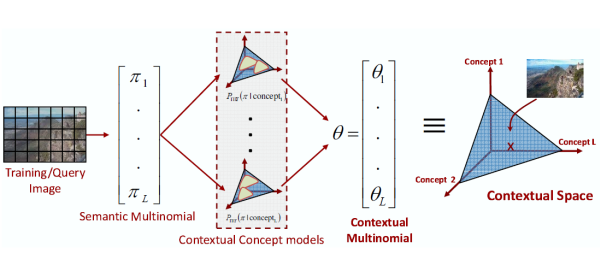
In this work, we investigate an approach to context modeling based on the probability of co-occurrence of objects and scenes. This modeling is quite simple, and builds upon the availability of robust appearance classifiers. A vocabulary of visual concepts is defined, and statistical models learned for all concepts, with existing appearance modeling techniques. These techniques are typically based on the bag-of-features (BoF) representation, where images are represented as collections of spatially localized features. The outputs of the appearance classifiers are then interpreted as the dimensions of a semantic space, where each axis represents a visual concept (see QBSE project page for more details). This is illustrated in the figure below, where an image is represented by the vector of its posterior probabilities under each of the appearance models. This vector is denoted as a semantic multinomial (SMN) distribution. This semantic representation inherits many of the benefits of bag-of-features. Most notably, it is strongly invariant to scene configurations, an essential attribute for robust scene classification and object recognition, and has low complexity, a property that enables large training sets and good generalization. Its main advantage over bag-of-features is a higher level of abstraction. While the appearance features are edges, edge orientations, or frequency bases, those of the semantic representation are concept probabilities. We have previously shown that this can lead to substantially better generalization, by comparing the performance of nearest-neighbors classification with the two representations, in an image retrieval context. However, the semantic representation also has some limitations that can be traced back to bag-of-features. Most notable among these is a certain amount of contextual noise, i.e., noise in the probabilities that compose the SMN. This is usually not due to poor statistical estimation, but due to the intrinsic ambiguity of the underlying bag-of-features representation. Since appearance based features have small spatial support, it is frequently difficult to assign them to a single visual concept. Hence, the SMN extracted from an image usually assigns some probability to concepts unrelated to it (e.g. the concepts ''bedroom'' and ''kitchen'' for the ''street'' image below). While the SMN representation captures co-occurrences of the semantic concepts present in an image, not all these correspond to true contextual relationships. In fact, we argue that many (e.g. ''bedroom'' and ''kitchen'' in the figure below) are accidental, i.e., casual coincidences due to the ambiguity of the underlying appearance representation (image patches that could belong to either a bed or a kitchen counter). Rather than attempting to eliminate contextual noise by further processing of appearance features, we propose a procedure for robust inference of contextual relationships in the presence of accidental co-occurrences. The idea is to keep the robustness of the appearance representation, but perform the classification at a higher level of abstraction, where ambiguity can be more easily detected. This is achieved by introducing a second level of representation, that operates in the space of semantic features. The intuition is that, in this space, accidental co-occurrences are events of much smaller probability than true contextual co-occurrences: while ''street'' co-occurs with ''buildings'' in most images, it accidentally co-occurs with ''bedroom'' or ''kitchen'' in a much smaller set. True contextual relationships can thus be found by identifying peaks of probability in semantic space. Each visual concept is modeled by the distribution of the posterior probabilities extracted from all its training images. This distribution of distributions is referred as the contextual model for the concept. For large enough and diverse enough training sets, these models are dominated by the probabilities of true contextual relationships. Minimum probability of error (MPE) contextual classification can thus be implemented by simple application of Bayes' rule. This suggests representing images as vectors of posterior probabilities under the contextual concept models, which we denote by contextual multinomials (CMN). These are shown much less noisier than the SMNs learned at the appearance level. |
|
|
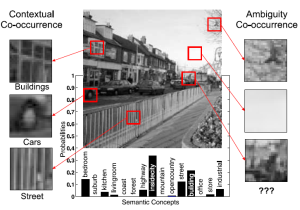
An image from the street class of the N15 dataset along with its SMN. Also highlighted are the two notions of co-occurrence --- ambiguity co-occurrences on the right: image patches compatible with multiple unrelated classes; contextual co-occurrences on the left: patches of multiple other classes related to street. |
|
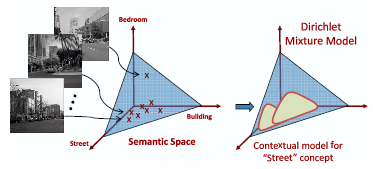
Learning the contextual model for the ''street'' concept, on semantic space from the set of all training images annotated with ''street''. |
| Results: |
Semantic Multinomials(SMN) vs Contextual Multinomials(CMN) Other Results |
| Poster: | CVPR'09 (pptx) |
| Databases: |
We have evaluated the proposed context modeling system on three different vision tasks using standard benchmark datasets:
Scene Classification
|
| Publications: |
Holistic Context Models for Visual Recognition
N. Rasiwasia and N. Vasconcelos Accepted to appear in IEEE Transactions on Pattern Analysis and Machine Intelligence, © IEEE [ps] [pdf] [supplement/ps] [supplement/pdf] |
|
Holistic Context Modeling using Semantic Co-occurrences N. Rasiwasia and N. Vasconcelos In, IEEE Conference on Computer Vision and Pattern Recognition, Miami, June 2009 © IEEE [ps] [pdf] | |
|
Image Retrieval using Query by Contextual Example N. Rasiwasia and N. Vasconcelos ACM Conference on Multimedia Information Retrieval, pp. 164-171, Vancouver, Oct 2008 © IEEE [ps] [pdf] | |
| Contact: | Nuno Vasconcelos, Nikhil Rasiwasia |
![]()
©
SVCL