|
Nikhil Rasiwasia received B.Tech degree in electrical engineering form Indian Institute of Technology Kanpur, (India)
in 2005. He received the MS and PhD degrees from the University of California, San Diego in 2007 and
2011 respectively, where he was a graduate student researcher at the Statistical Visual Computing Laboratory, in
the ECE department. Currently, he is working as scientist for Yahoo Labs! Bangalore, India. In 2008, he was
recognized as an `Emerging Leader in Multimedia' by IBM T. J. Watson Research.
He also received the best student paper award at ACM Multimedia conference in
2010. His research interests are in the areas of computer vision and machine
learning, in particular applying machine learning solutions to computer vision
problems.
Curriculum Vitae: pdf
Personal Web Page: Confusion Art
|
| Research: |
| |
My research interests are in the areas of computer
vision, pattern recognition, and machine learning. In
particular, I aim to develop probabilistic models of
images that can be applied to computer vision problems,
such as image annotation, image retrieval, scene
classification, object detection and localization, image
segmentation etc.
|
Publications:
|
| |
| Phd Thesis: |
| |
Semantic Image Representation for Visual Recognition
N. Rasiwasia
University of California, San Diego, Sept 20111,
[pdf(s)/pptx]
|
|
| Journal Articles: |
| |
Endoscopic image analysis in semantic space
R. Kwitt, N. Vasconcelos, N. Rasiwasia, A. Uhl, B. Davis, M. Hafner and F. Wrba
Medical Image Analysis, vol. 16(7), 1415-1422, October 2012
[ps] [pdf]
|
| |
Holistic Context Models for Visual Recognition
N. Rasiwasia and N. Vasconcelos
IEEE Transactions on Pattern
Analysis and Machine Intelligence,
May 2012, 34(5): 902-917
[ps]
[pdf]
[supplement/ps]
[supplement/pdf]
|
| |
Bridging the Semantic Gap: Query by Semantic
Example
N. Rasiwasia P. J. Moreno and N. Vasconcelos
IEEE Trans. on Multimedia,
Vol. 9(5), pp. 923-938, August 2007 ©
IEEE [ps]
[pdf]
|
| |
Generative Models for Image Classification
N. Rasiwasia and N. Vasconcelos
Submitted to IEEE Transactions on Pattern Analysis and Machine Intelligence,
© IEEE
|
| |
On the Role of Correlation and Abstraction in Cross-Modal Multimedia Retrieval
J. Costa Pereira, E. Coviello, G. Doyle, N. Rasiwasia, G.R.G. Lanckriet, R. Levy and N. Vasconcelos
Submitted to IEEE Transactions on Pattern Analysis and Machine Intelligence,
© IEEE
|
|
| Conference Papers: |
| |
Scene Recognition on the Semantic Manifold
R. Kwitt, N. Vasconcelos, N. Rasiwasia
Proceedings of IEEE European Conference on Computer
Vision (ECCV)
Firenze, Italy, 2012 [ps] [pdf]
Adapted Gaussian Models for Image Classification
M. Dixit, N.
Rasiwasia and N. Vasconcelos
In,
IEEE Conference on Computer Vision and Pattern Recognition, Colorado Springs, June 2011
© IEEE
[ps]
[pdf]
Improving Product Classification Using Images
A. Kannan, P. Talukdar, N. Rasiwasia and Q. Ke
In, IEEE International Conference on Data Mining,
Vancouver, Dec 2011
© IEEE
[to appear]
Learning Pit Pattern Concepts for Gastroenterological Training
R. Kwitt, N. Rasiwasia, N. Vasconcelos, A. Uhl, M. Hafner, F. Wrba
In,
In Proceedings of the International Conference on Medical Image Computing and Computer Assisted Intervention (MICCAI '11)
, Toronto, Sept 2011
[ps]
[pdf]
A New Approach to Cross-Modal Multimedia
Retrieval [ORAL] [Best-student paper]
In, ACM Proceedings of the 18th international conference on Multimedia,
Florence, Oct 2010
© IEEE
[ps]
[pdf]
Holistic Context Modeling using Semantic Co-occurrences N. Rasiwasia and N. Vasconcelos
In, IEEE Conference on Computer Vision and Pattern Recognition,
Miami, June 2009
© IEEE
[ps]
[pdf]
Image Retrieval using Query by Contextual Example N. Rasiwasia and N. Vasconcelos
ACM Conference on Multimedia Information Retrieval,
pp. 164-171, Vancouver, Oct 2008
©
IEEE [ps]
[pdf]
A Systematic Study of the role of Context on Image Classification N. Rasiwasia and N. Vasconcelos
IEEE Conference on Image Processing,
pp. 1720-1723, San Diego, Oct 2008 ©
IEEE [ps]
[pdf]
Scene Classification with Low-dimensional Semantic Spaces and Weak Supervision N. Rasiwasia and N. Vasconcelos
IEEE Conference on Computer Vision and Pattern Recognition,
pp. 1-6, Anchorage, June 2008
©
IEEE [ps]
[pdf]
A study of Query by Semantic Example N. Rasiwasia and N. Vasconcelos
CVPR Workshop on Semantic Learning and Applications in Multimedia,
Anchorage, Alaska, June 2008
©
IEEE [ps]
[pdf]
Query by Semantic Example
N. Rasiwasia, P. J. Moreno and N.
Vasconcelos
ACM International Conference on Image and Video
Retrieval,
LNCS 4071, pp. 51-60, Phoenix, 2006 [ORAL] ©
IEEE [ps]
[pdf]
|
| Bachelor Thesis: |
| |
The Avatar: 3D Face Reconstruction from two
orthogonal pictures
N. Rasiwasia and K. S. Venkatesh
Indian Institute of Technology, Kanpur, May 2005
[pdf]
|
|
Selected Talks:
|
| |
Cross-Modal Multimedia Retrieval
Yahoo Labs Bangalore, India, Nov 2010
Context Models for Visual Recognition
Microsoft Research Bangalore, India, Nov 2010
Google Inc., Mountain View, CA, Sept 2009
FX Palo Alto Laboratory, Inc., Palo Alto, CA, August 2009
Microsoft Research Silicon Valley, Mountain View, CA, July 2009
Hierarchical Semantic Representation for Image Retrieval
Southern California Computer Vision Meetup, UC Irvine, CA, Oct 2008
Emerging Leaders in Multimedia, IBM T. J. Watson Research Center, NY, Oct 2008
Computer Vision and Photography
Photography Club, DreamWorks (Technicolor), Bangalore, India, Nov 2010
|
Main Projects:
|
| |
LDA models for image classification
[coming soon]
|
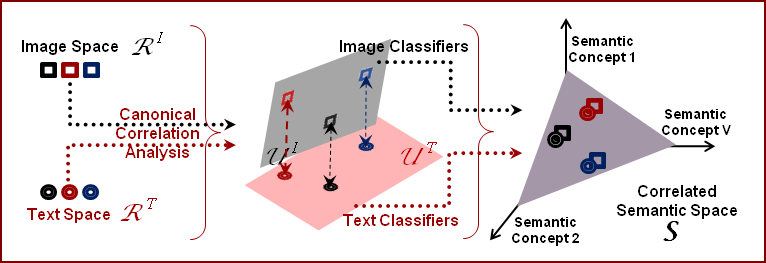
Cross-Modal Multimedia Retrieval
The problem of joint modeling text and image components
of multimedia documents is studied.
Two hypotheses are investigated:
that 1) there is a benefit to explicitly modeling
correlations between the two components,
and 2) this modeling is more effective in feature
spaces with higher levels of abstraction.
[project] |
 |
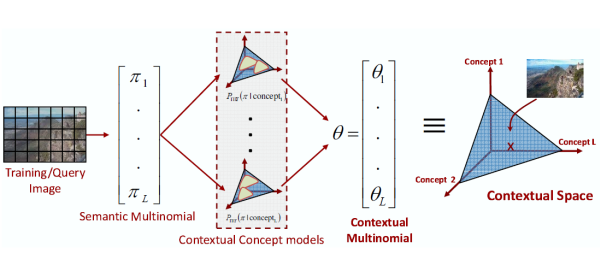
Holistic Context Models for Visual Recognition.
In this work, we investigate an approach to context modeling based
on the probability of co-occurrence of objects and scenes. This
modeling is quite simple, and builds upon the availability of
robust appearance classifiers.
[project|examples] |
 |
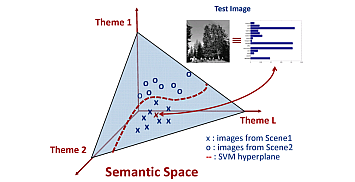
Scene Classification with Low-dimensional Semantic Spaces
A novel approach to scene categorization is proposed. An intermediate space is
introduced, based on a low dimensional semantic "theme" image representation.
However, instead of learning the themes in an unsupervised manner, they are
learned with weak supervision, from casual image annotations.
[project] |
 |
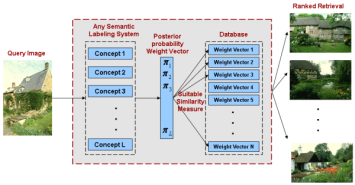
Query By Semantic Example
The long term goal of this ongoing project is to successfully
retrieve images in a manner that is semantically meaningful to a human
observer. A semantic space is defined, where each of the axis represents a
semantic concept from a given vocabulary. Images are then represented
on this semantic space as vectors of posterior concept probabilities.
Extensive objective evaluation shows benefits of the proposed semantic representation,
over system based on traditional low-level visual features.
[project | demo] |
 |
|
Past Projects:
|
| |
Surveillance Video Entertainment Network
Dept Of Visual Arts, UCSD
The software consists of a custom computer
vision application that tracks pedestrians and detects their characteristics,
and a real-time video processing application that receives this information and
uses it to generate music-video like visuals from the live camera feed.
[project] |
 |
The Avatar - Virtual 3-D Facial Makeover
IIT Kanpur
An algorithm for the fast reconstruction of
a textured 3-D face model of a given individual from his two orthogonal
pictures a frontal view and a profile view is presented. Initially the facial
features are identified and extracted giving the coordinated of the feature
points, and then a generic model is deformed using Radial Basis Functions
(RBF).
[project] |

 |
Real Time Robust Tracking of Human Hand
University of Trento, Italy
Detection and tracking of human hand in real
time under varying illumination conditions and various skin tones was explored.
Subsequent recognition of simple gestures gestures were also implemented.
[project] |
|
Age Invariant Face Recognition
IIT Kanpur
The aim of this project was to find the
facial features which remain invariant or transform in a predetermined way with
age, thus establishing a match between the childhood and adult frontal face
photograph of the same individual.
[project] |
 |
|
Code
|
| |
LDA-C with Assymetric Prior
This is a modified version of the LDA-C code provided by David M. Blei
with the functionaly to learn an assymetric prior (different alpha values for
different topics) instead of a having them equal for all the topics.
|
Other Interesting Suff :)
|
| |
|

